Operationalizing Distributed AI: Armada and NVIDIA AI Grid



Real-time AI is reshaping infrastructure requirements.
Inference workloads such as conversational AI, real-time video generation, AR/XR streaming, visual search, and large-scale personalization demand ultra-low latency, predictable performance, and geographic proximity to users and data sources. Centralized AI factories remain essential for training, but for many AI-native services, inference at scale requires AI Grids: geographically distributed GPU infrastructure operating as a unified, policy-controlled system.
Armada is collaborating with NVIDIA to enable NVIDIA AI Grid on Armada Edge Platform (AEP), providing telecommunications operators, service providers, and enterprises with a validated architecture for deploying and operating distributed AI infrastructure at global scale.
This post explores the architecture and operational model behind that system.
Reference Architecture: NVIDIA AI Grid + Armada Edge Platform
Armada Edge Platform is aligned with the NVIDIA AI Grid reference design and integrates with key NVIDIA technologies, including: NVIDIA RTX PRO Servers, NVIDIA HGX B200 systems, NVIDIA Spectrum-X Ethernet networking, NVIDIA BlueField DPUs, and NVIDIA AI Enterprise software.
Together, these components form a distributed AI infrastructure stack designed for production-scale inference across centralized and edge environments.
Where NVIDIA provides the accelerated compute, networking, and software stack, Armada provides the distributed control plane and operational layer required to manage this infrastructure coherently across thousands of locations.
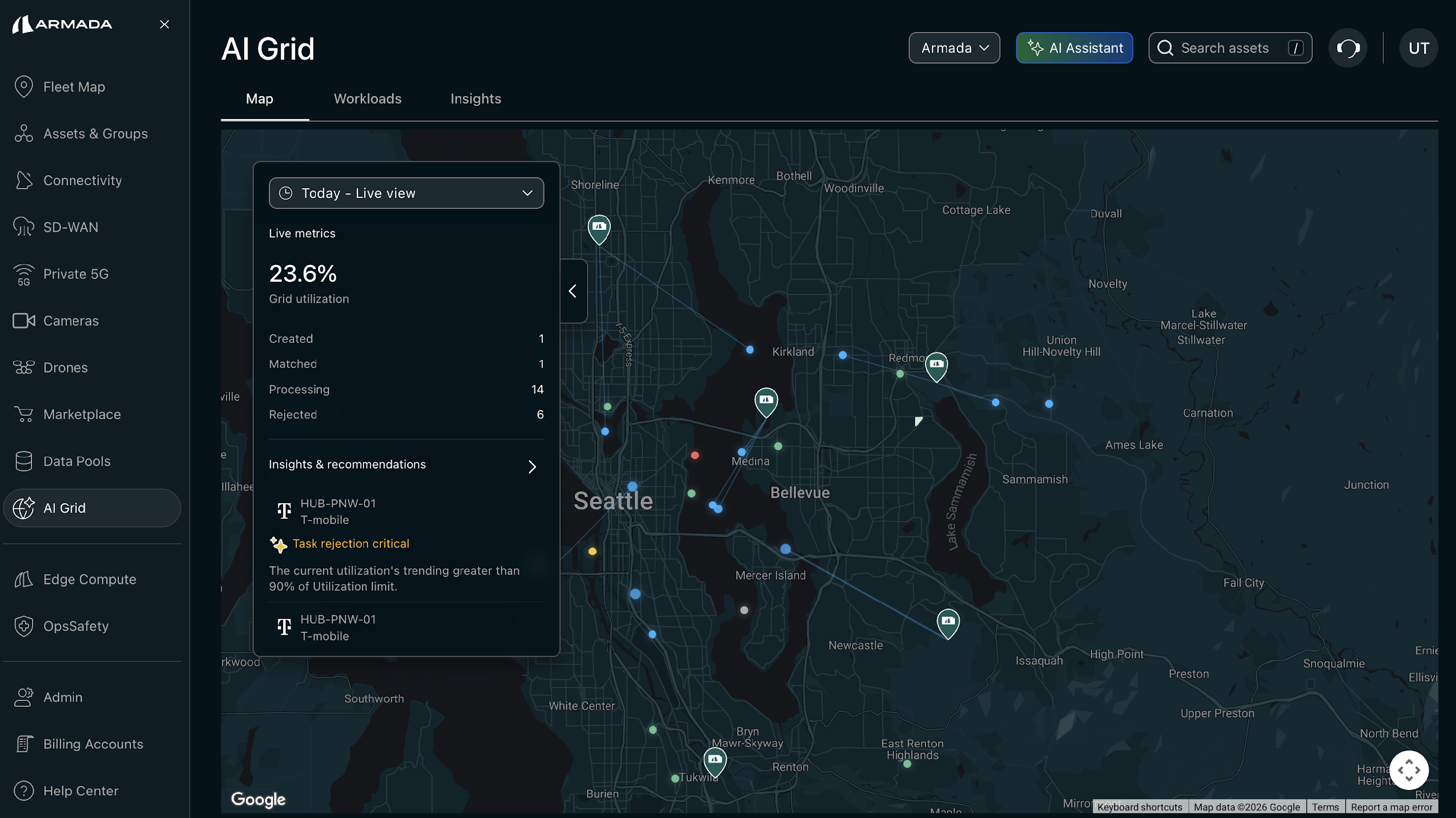 Live view of AI Grid
Live view of AI Grid
The Core Challenge: Distributed GPUs as One System
Deploying GPUs at multiple sites is not equivalent to operating a distributed AI platform.
AI Grid deployments must support:
- Unified lifecycle management
- Deterministic workload placement
- Resource-aware scheduling
- Secure multi-tenancy
- Policy-based network control
- Centralized observability
- Compliance-aware orchestration
Armada Edge Platform provides a unified control plane spanning centralized AI factories, regional hubs, and edge locations.
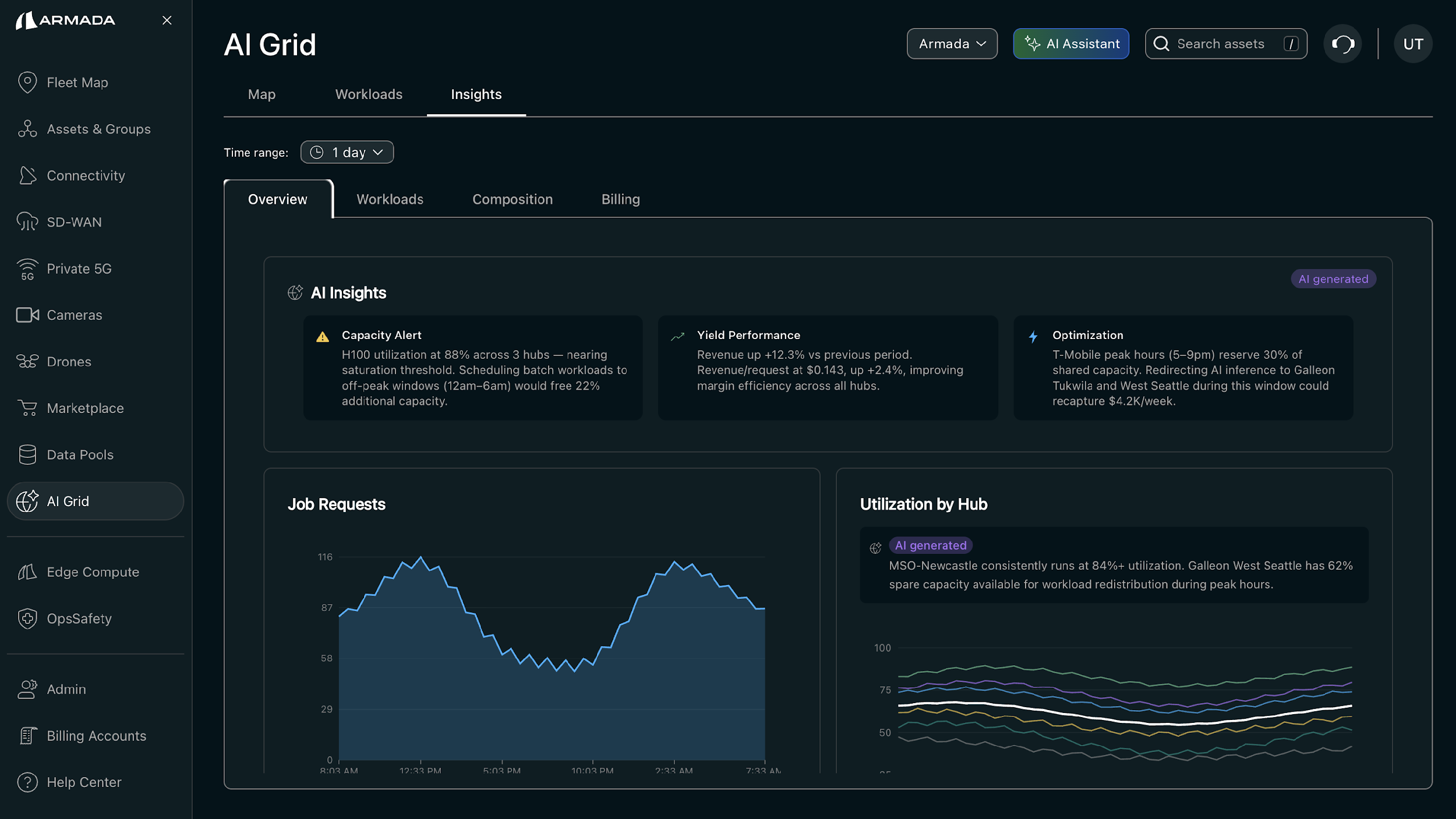 Monitoring and Observability for AI Grid
Monitoring and Observability for AI Grid
Rather than treating each GPU site as an isolated cluster, AEP stitches distributed GPU infrastructure into a single operational domain. This enables:
- Workload-aware and resource-aware orchestration across sites
- Intelligent placement decisions based on latency, proximity, GPU utilization, cost, compliance, and policy
- Consistent software lifecycle management across hundreds to thousands of locations
- Centralized monitoring and observability across the AI Grid
The result is a globally distributed GPU fabric that behaves like a coherent platform.
Orchestration Model: Latency- and Policy-Aware Placement
AI inference workloads differ significantly from traditional cloud workloads. They are often latency-sensitive, data-locality constrained, burst-driven, GPU-intensive, and multi-tenant in nature.
AEP's orchestration layer evaluates placement decisions across multiple dimensions:
- Latency requirements
- Proximity to users and data sources
- Real-time GPU availability and utilization
- Network characteristics
- Cost models
- Regulatory and compliance policies
This enables deterministic and optimized inference placement across distributed sites.
For example, conversational AI workloads can be pinned close to users for minimal response time, while batch inference or less sensitive workloads can be placed in regional hubs or centralized AI factories, all under a single operational framework.
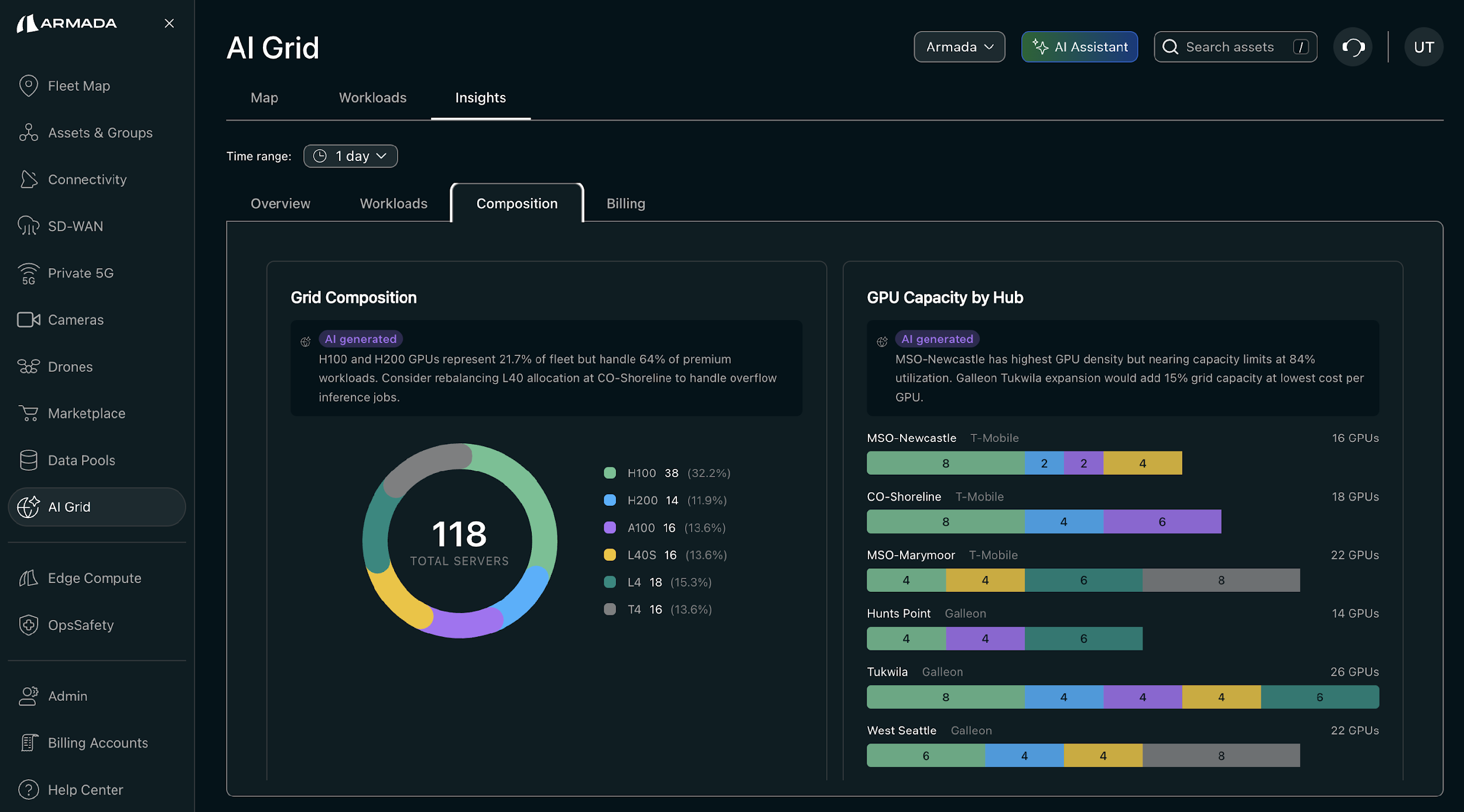 Grid Capacity and Composition
Grid Capacity and Composition
Each AI Grid location operates as a secure, multi-tenant environment.
Armada platform layer supports Bare metal provisioning, virtual machines, storage and networking services, managed Kubernetes, Model-as-a-Service, managed SLURM, Jupyter notebooks, and end-to-end ML workflows.
Isolation is enforced across CPU, GPU, network, and storage resources to ensure strong tenant separation, predictable performance, compliance alignment, and maximized GPU efficiency. This allows operators to safely expose distributed GPU capacity as monetizable services, including GPUaaS and inference platforms.
Network Integration: Deterministic AI Delivery
AI Grid performance depends not just on GPUs but on network architecture.
Armada Edge Platform integrates directly with the service provider's network layer to establish dedicated, policy-controlled connectivity from data sources to GPU workloads.
This ensures predictable latency, secure data paths, traffic isolation, QoS enforcement, and end-to-end performance guarantees. By combining distributed GPU placement with network-aware orchestration, AI inference becomes a deterministic system rather than a best-effort deployment.
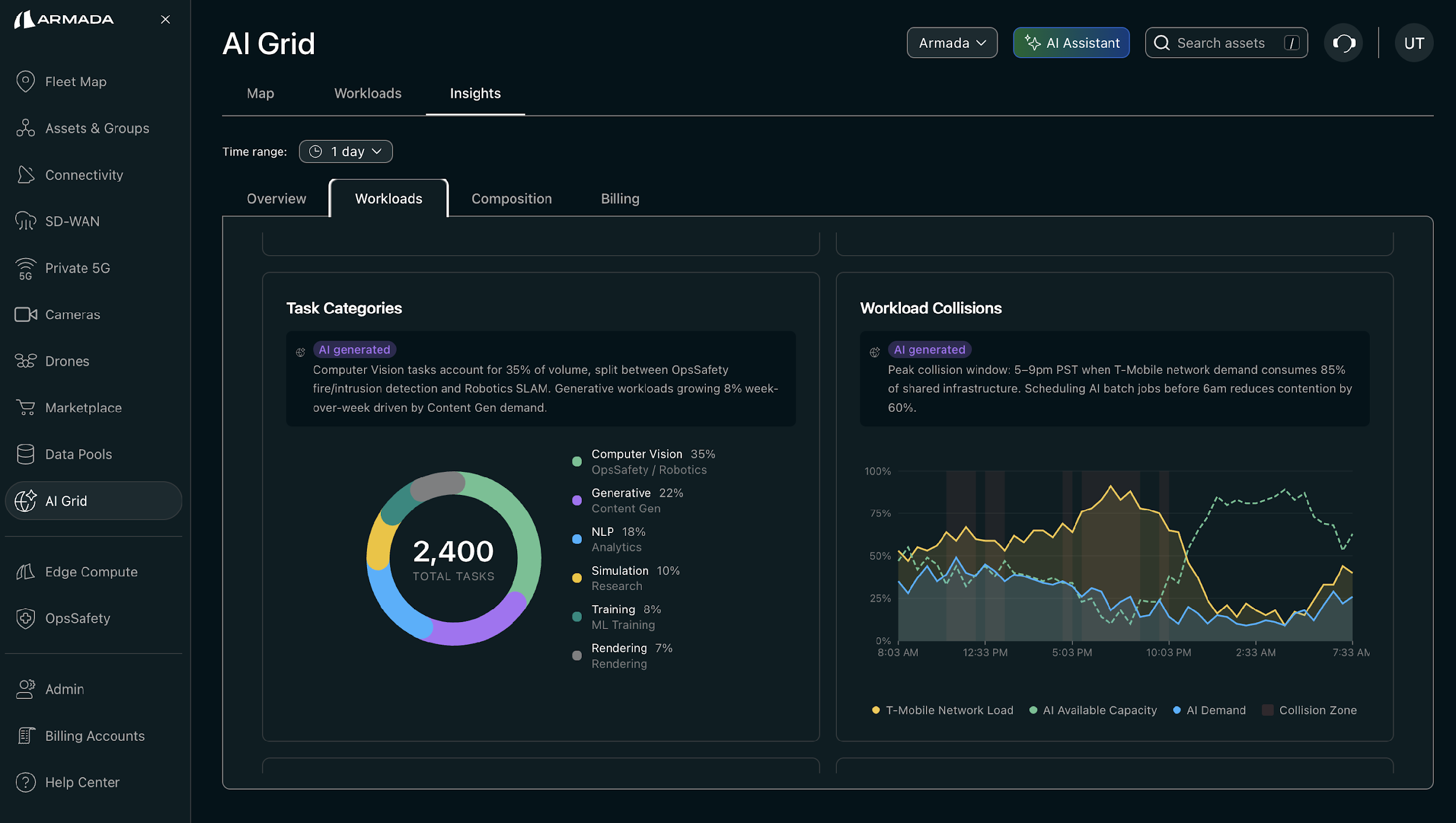 AI Grid Workload Allocation
AI Grid Workload Allocation
Physical Infrastructure: Data Centers as AI Grid Foundation
Distributed AI requires standardized infrastructure at the physical layer. AEP supports AI Grid across brick-and-mortar data centers as well as Armada's Galleon modular data centers when data centers are unavailable or can't be built rapidly enough.
Galleon, Armada's modular data center platform, provides a ruggedized, rapidly deployable, high-density AI infrastructure foundation for AI Grid deployments.
Galleon integrates Power systems, Cooling, Networking, Compute and Storage into a standardized, edge-ready form factor. This enables accelerated deployment timelines, consistent hardware profiles across sites, repeatable rollout models along with edge and remote environment operations.
When combined with AEP's control plane, Galleon allows operators to treat distributed AI infrastructure as a scalable system rather than a collection of bespoke deployments.
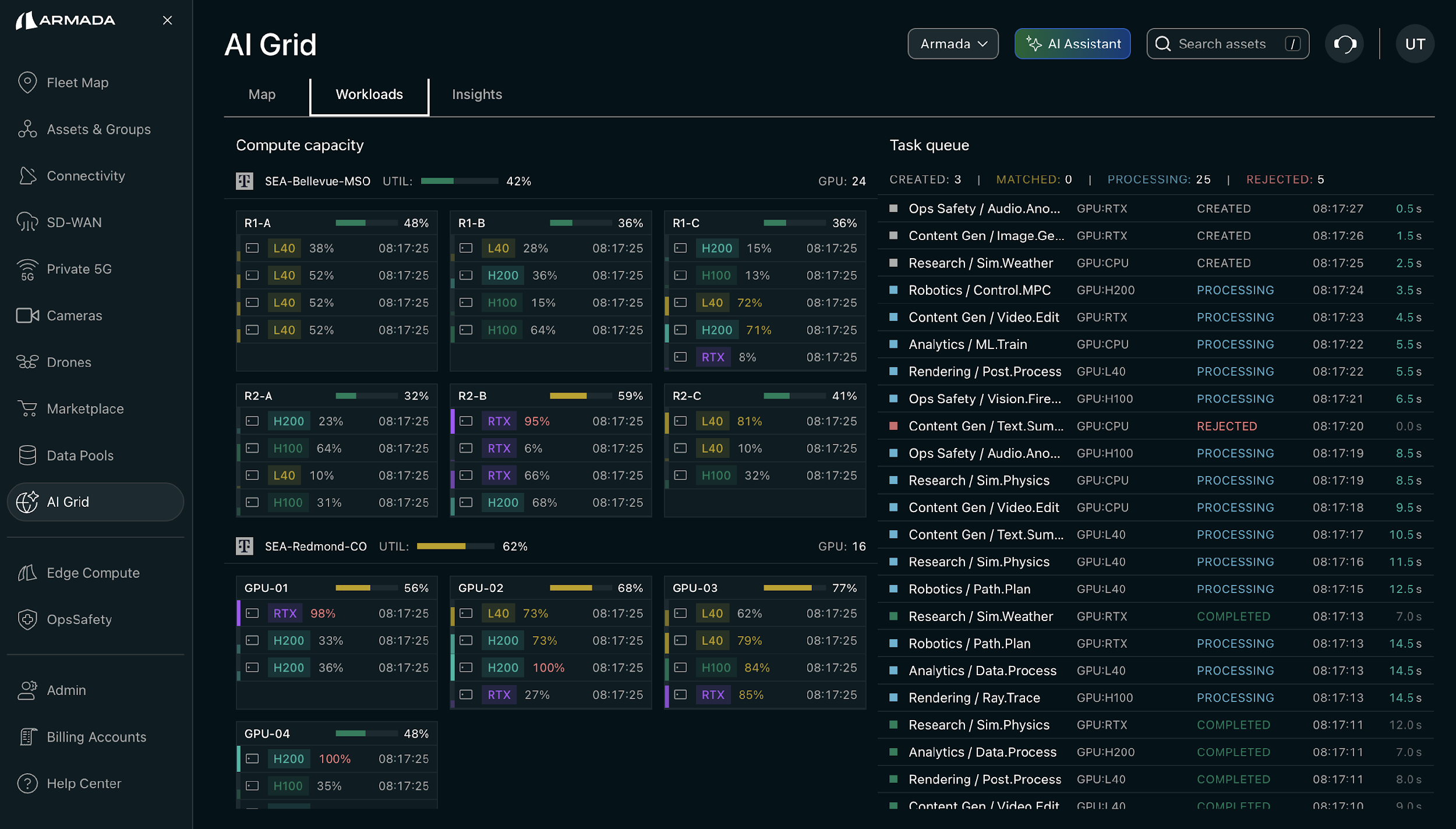 AI Grid workload allocation
AI Grid workload allocation
From GPU Infrastructure to Revenue Infrastructure
The transition to AI Grids is not solely a technical evolution but it is an economic one.
Telecommunications operators and service providers can leverage distributed GPU infrastructure to:
- Offer low-latency AI inference services
- Support enterprise AI workloads at the edge
- Enable real-time consumer AI applications
- Provide GPUaaS across geographic markets
Armada provides the operational layer that transforms geographically distributed GPU deployments into unified, revenue-generating AI platforms, including sovereign GPU cloud.
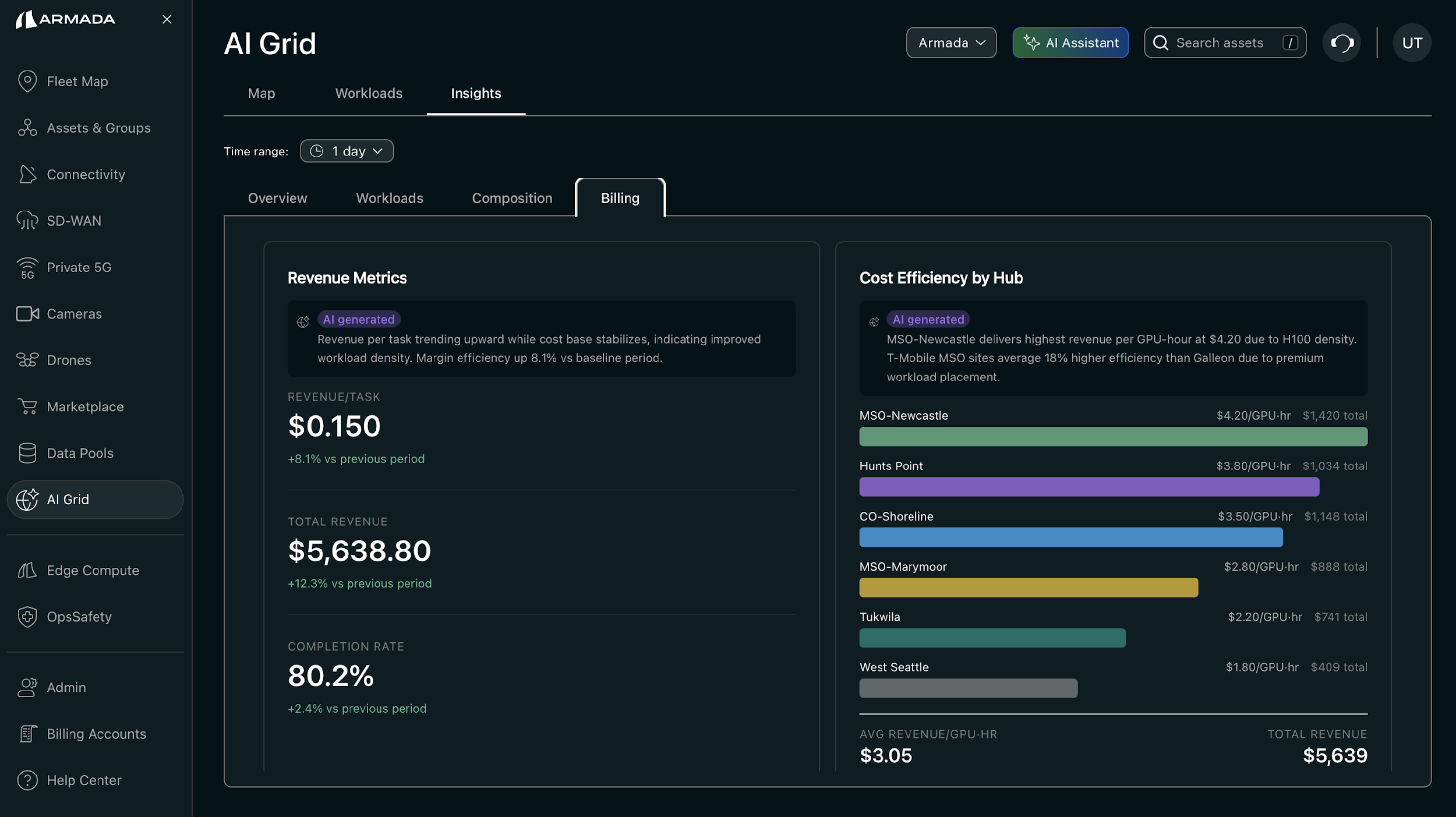 AI Grid Revenue Metrics and Cost Optimization
AI Grid Revenue Metrics and Cost Optimization
By abstracting complexity across hardware, networking, orchestration, and lifecycle management, AEP enables operators to scale AI infrastructure from dozens to thousands of sites without multiplying operational overhead.
The Architecture of Distributed AI at Scale
The next phase of AI infrastructure is defined by distribution, orchestration intelligence, and operational consistency.
NVIDIA AI Grid provides the accelerated computing foundation. Armada provides the distributed control plane and a physical deployment model through its Galleon and AEP.
Together, this architecture enables AI infrastructure that is geographically distributed, operationally unified, network-aware, secure and multi-tenant, and policy-driven that is scalable to thousands of locations.
Finally, distributed inference is no longer an edge experiment and has become core infrastructure. The AI Grid era is here, and it requires systems built to operate everywhere, as one.