Telecommunications and AI Grid
Telecommunications operators are increasingly deploying GPU infrastructure to offer AI services to their customers. Unlike traditional cloud providers, telecom operators operate large, distributed networks of facilities, including centralized data centers, regional hubs, and edge locations connected to 5G infrastructure. These service providers are uniquely positioned to deliver low-latency AI services close to users and data sources.
When GPU infrastructure is deployed in centralized telecom data centers, the operational and economic challenges closely resemble those of Neocloud operators. Telecommunications providers invest significant capital in GPU hardware and must maximize the return on that investment while ensuring reliable service delivery.
At the same time, many telecom operators are extending GPU infrastructure across distributed locations to support real-time AI applications. This is driving the emergence of AI Grids, where geographically distributed GPU resources operate as a unified system spanning centralized AI factories, regional hubs, and edge locations.
Problem
Telecommunications providers face several challenges when deploying AI infrastructure.
-
Monetization of GPU infrastructure: Like Neocloud operators, telecom providers must convert GPU investments into revenue-generating services. Operators must maximize GPU utilization, maintain high average selling price per GPU, and ensure infrastructure uptime while minimizing operational expenses.
-
Monetizing unused capacity: Not all GPU capacity can be allocated to long-term enterprise customers. Operators must find ways to monetize unused GPU resources through services such as:
- On-demand elastic IaaS instances such as bare metal, virtual machines, or containers
- Managed Kubernetes or other PaaS platforms
- AI development environments and MLOps platforms
- Model hosting or LLM-as-a-Service offerings
- Shared multi-tenant AI services
- Integration with GPU marketplaces
Each of these service models requires secure multi-tenancy, automation, and operational tooling.
-
Distributed infrastructure: Telecommunications networks may include dozens or hundreds of potential GPU locations across centralized data centers, regional facilities, and edge sites which creates a significant management burden.
-
Latency-sensitive workloads: Applications such as conversational AI, video analytics, AR/VR streaming, and real-time personalization require inference to run close to users and data sources to achieve acceptable response times.
-
Intelligent workload placement: AI workloads must be scheduled across distributed infrastructure based on factors such as latency requirements, network characteristics, GPU availability, cost models, and regulatory constraints.
Without a unified platform, operating distributed GPU infrastructure quickly becomes difficult to manage.
Solution
Bridge is a GPU management platform that enables operators to deliver GPU infrastructure as Infrastructure-as-a-Service (IaaS), Platform-as-a-Service (PaaS), and AI-as-a-Service (AIaaS). Bridge provides secure multi-tenancy, lifecycle management, and operational automation across GPU clusters, allowing operators to safely share GPU infrastructure among multiple tenants while maximizing utilization and simplifying operations.
Using Bridge, telecommunications providers can rapidly transform GPU infrastructure into a monetizable AI platform capable of offering services such as:
- GPU Infrastructure-as-a-Service
- Managed Kubernetes platforms
- AI developer environments and MLOps frameworks
- Model hosting and inference platforms
- Shared multi-tenant AI services
Bridge provides secure multi-tenancy across CPU, GPU, network, Infiniband, NVLink, storage, and WAN resources, ensuring tenants can safely share infrastructure without impacting each other's performance or security.
Operational capabilities include:
- Observability and monitoring
- Alerts and fault management
- Centralized logging
- Lifecycle management for clusters and software
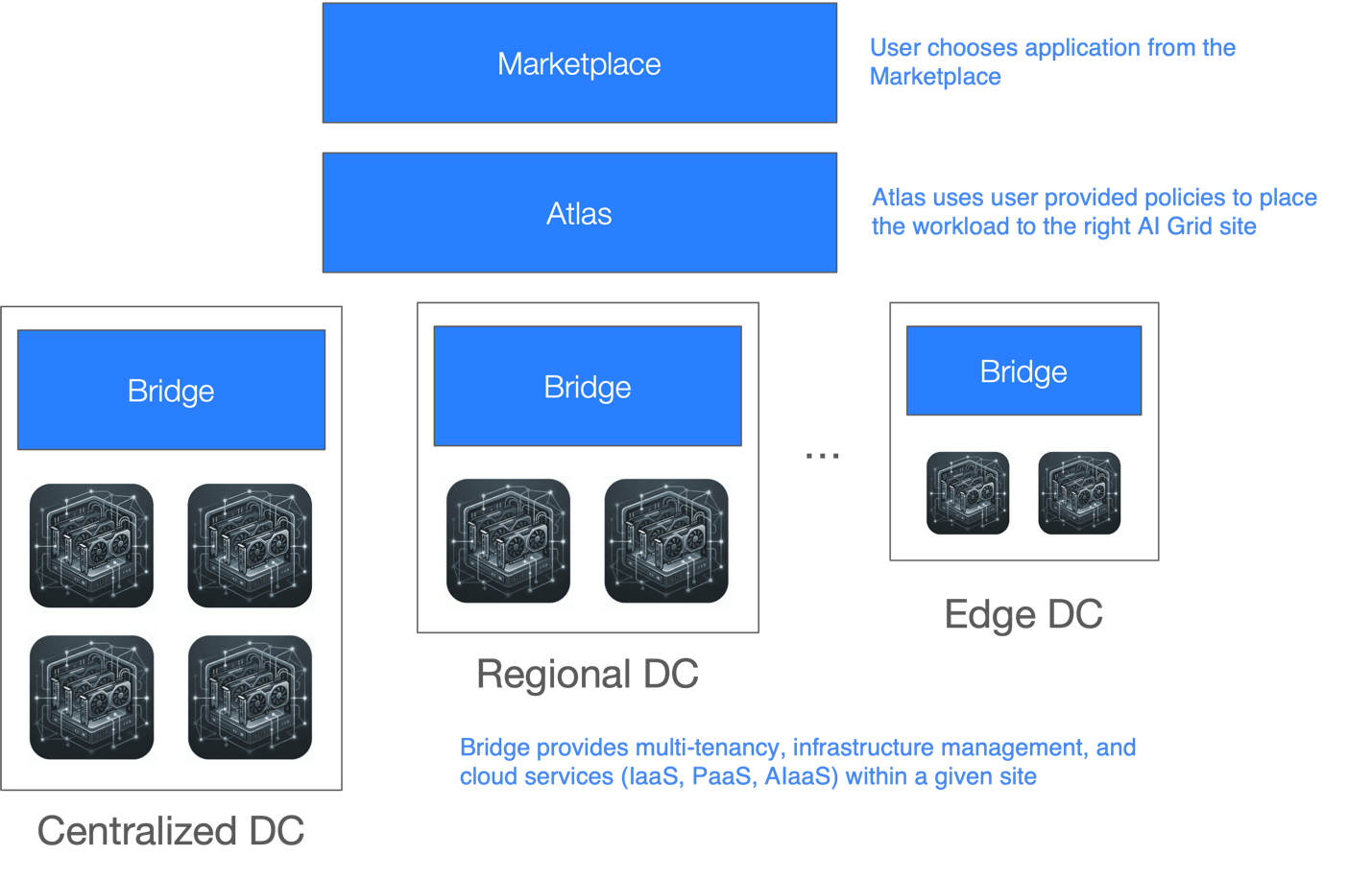
For distributed AI Grid environments, Bridge can be combined with Armada Atlas and Marketplace, which provide a catalog of applications and edge site management and intelligent workload placement across geographically distributed infrastructure. Atlas connects centralized AI factories, regional hubs, and edge locations into a unified operational platform and places workloads based on factors such as:
- Latency requirements
- Proximity to users and data sources
- GPU availability and utilization
- Network characteristics
- Cost models
- Regulatory and compliance policies
Bridge also integrates with telecom network infrastructure, including 5G local breakout and service provider network fabrics, to provide dedicated connectivity from data sources to GPU workloads. This enables predictable latency, secure data paths, and end-to-end performance guarantees.
For service providers without traditional data center facilities, Armada can also provide modular data centers branded Galleon, enabling rapid deployment of standardized AI infrastructure at edge or regional locations.
Together, Bridge, Atlas, and Galleon enable telecommunications providers to deploy distributed GPU infrastructure across their networks and operate it as a unified AI Grid platform capable of delivering the next generation of real-time AI services.