Reference Architecture
Motivation for On-Demand Multi-tenancy
With GPUs being refreshed every year, NVIDIA Cloud Partners1 (NCPs) need new ways to monetize their GPUs to get a meaningful return on their investment. Armada’s NCP ROI calculator2 shows the following:
- Moving from a static/manual allocation of GPU resources to a self-service on-demand multi-tenancy model for unused GPUs can improve the internal rate of return (IRR) by 4x. This approach allows NCPs to expand their market from just LLM training to inference, fine tuning, and more.
- Adding on a Platform-as-a-Service layer (job submission and model serving) can improve the IRR by an additional 5x resulting in a total 20x improvement as compared to the original approach.
Thus, the need for dynamic, self-service/API-driven, multi-tenant access to AI cloud infrastructure has become a critical requirement for NVIDIA Cloud Partners (NCPs) and AI Cloud Providers. Organizations increasingly require solutions that combine multi-tenancy with on-demand scalability to address diverse end-user needs, spanning from Infrastructure-as-a-Service (IaaS) to Platform-as-a-Service (PaaS).
If an NCP decided to proceed with building out additional cloud capabilities, they are left with the following approaches:
- Do-it-Yourself: In this approach, the NCP would hire a team of 15-20 experts and build out a solution over 18-24 months. Each NCP has to determine if this approach makes sense in their given situation.
- Bag-of-Tools: In this approach, the NCP would choose a variety of different tools such as network multi-tenancy, Kubernetes (K8s) management, billing, user management etc. The approach is less painful than Do-it-Yourself, but not by much.
- Comprehensive Solutions: In this approach, the NCP would choose vendors, such as Armada, that provide a comprehensive IaaS (across network, InfiniBand, storage, CPU, and GPU) + PaaS solution.
However, building such a comprehensive solution needs to address challenges summarized below:
- Need for a unified multi-tenancy solution: The designs and solutions available today for implementing multi-tenancy in AI cloud infrastructure are fragmented across infrastructure stacks such as compute, networking, storage, and PaaS. These silos make it challenging to onboard tenants seamlessly while maintaining consistent isolation and automation. A unified, coherent approach is needed to simplify tenant onboarding, ensure the use of optimal isolation techniques, and eliminate manual intervention during this process.
- Supporting diverse use cases on a single platform: To remain competitive and extend their value proposition, NCPs and AI cloud providers must cater to a variety of business use cases. This includes evolving from static bare-metal GPU allocations to dynamic offerings that include PaaS capabilities and ultimately delivering Job Submission and Model Serving. Achieving this requires the ability to dynamically repurpose the same AI cloud infrastructure for different customer needs while maintaining operational efficiency and leveraging common tooling.
- Maximizing GPU utilization: Modern AI workloads are diverse, encompassing tasks like training Large Language Models (LLMs) and Small Language Models (SLMs), fine-tuning, distilling, DL training, batch inference, real-time inferencing, and Retrieval-Augmented Generation (RAG). These workloads have highly varied GPU utilization patterns, which can lead to resource inefficiencies if not managed properly. There is a pressing need for a robust, intelligent orchestration that can optimize GPU usage by dynamically scaling the infrastructure of each workload while ensuring efficient resource allocation.
Comprehensive Blueprint for Multi-Tenant AI Cloud Infrastructure
Armada on-demand multi-tenancy Reference Architecture (RA) provides a holistic solution to solve the above problems by offering a blueprint for implementing a self-service, on-demand, multi-tenant platform. It supports GPU infrastructure management and PaaS offerings, enabling providers to achieve:
- Unified Multi-Tenancy Management: Seamlessly onboard tenants with automated workflows, ensuring optimal isolation strategies, and eliminating manual effort.
- Flexible Service Offerings: Deliver both Infrastructure-as-a-service (IaaS) and Platform-as-a-service (PaaS) services, ranging from bare-metal and virtual machine provisioning to Kubernetes-based solutions, model serving, job scheduling, all with dynamic GPU allocation.
- Enhanced Resource Utilization: Implement an efficient orchestrator to ensure optimal GPU usage, maximizing infrastructure ROI for diverse workloads.
Armada GPU Cloud Management Software (Bridge) is the central piece of this comprehensive RA. By leveraging this, NCPs and AI Cloud Providers can dynamically extend their infrastructure to support dynamic workloads, serverless applications, and advanced AI/ML use cases.
Deployment Architecture
This section describes typical topology that NCPs / AI cloud providers utilize. The topology can scale from a relatively small one (with just 8 GPUs) to a large-scale deployment of thousands of GPUs. The topology is depicted below.
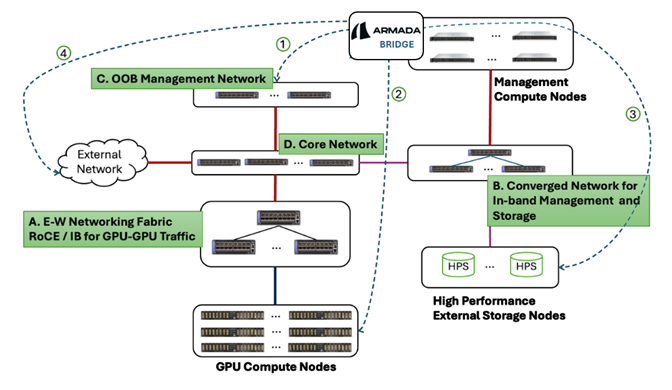 Figure 1: Deployment architecture
Figure 1: Deployment architecture
Converged Network Topology
Deployment of AI cloud infrastructure in this topology comprises the following:
The specific hardware configuration mentioned here is meant to be for illustration only. NCPs or GPUaaS providers should follow the recommendation of the hardware vendor for optimal performance. Moreover, this document does not specify the switch connectivity topology and rail architecture, but uses the recommended topology from respective hardware vendors and their respective Reference Architecture.
-
Multi-tier networking fabric: The deployment comprises various layers of interconnected networking fabric to optimize data and management traffic. These network fabrics are (see also Figure 1 above):
- East-West Network Fabric: This network optimizes communication between GPUs and ensures that there are minimal hops when GPUs need to communicate between them. This can be either Ethernet based or InfiniBand based.
- If Ethernet is used, the typical configuration may use NVIDIA SpectrumX switches such as SN5600.
- If InfiniBand is used, the configuration may use NVIDIA QM9700 or similar switches. In the case of InfiniBand, the configuration typically also includes the NVIDIA UFM Appliance.
- Converged (North-South) Network Fabric: This network is intended for addressing north-south traffic to enable communication between GPU compute nodes, High Performance external Storage (HPS) nodes, in-band management of GPU compute nodes and optionally connecting to external gateways / routers. This can be either 2-tier or 3-tier topology, depending on the number of compute and storage nodes that need to be supported. Please refer to the recommendation from the hardware vendor.
- Out-of-band (OOB) Management Network: This network is used for managing bare metal compute, switch, and other hardware nodes using their BMC ports. The typical configuration consists of the NVIDIA SN2201 Switch. If the configuration uses NVIDIA Base Command Manager (BCM) or other tools for hardware provisioning, they need to be configured as part of this network.
- Core Network: This network connects all other networks in the AI cloud and is required only for large scale deployments. For smaller deployments, the network could be designed without this layer.
- East-West Network Fabric: This network optimizes communication between GPUs and ensures that there are minimal hops when GPUs need to communicate between them. This can be either Ethernet based or InfiniBand based.
-
GPU compute nodes: GPU compute nodes such as NVIDIA DGX/HGX or MGX are deployed in multiple scalable units and are connected to the E-W networking fabric for GPU-GPU communication. The compute nodes are connected to the Ethernet or InfiniBand fabric using the respective adapters such as Bluefield3 DPUs (as a network adapter) or InfiniBand ConnectX HCA.
-
High performance external storage nodes (HPS): Multiple external storage devices are deployed to enable the GPU compute nodes to persist their training data. These nodes are connected to a converged N-S network fabric.
-
Management nodes: These comprise general-purpose computing nodes where all the management software is typically deployed. Bridge needs to be deployed on a set of compute nodes depending on the high availability and scalability requirements. GPUs are NOT required for management nodes.
-
External network: This network comprises IP networking infrastructure such as Routers, Gateways, firewalls etc. that manage ingress / egress traffic. In Armada RA, these can be provided by the NCP’s preferred vendor of choice.
Bridge needs to be deployed on a set of the management compute nodes to perform the following:
- Bare metal management and configuration of GPU compute nodes and network switches. This shall be enabled through the OOB switching network.
- In-band management of GPU compute nodes involving deployment, configuration, and monitoring.
- Per tenant configuration of external storage devices.
- Configuration of external gateways / routes to enable ingress and egress traffic for tenant compute nodes or workloads.
- Overall management of the multi-tenant operations, including observability, and more.
Bridge deployment specifications
Bridge is a cloud native application and could be deployed on any standard K8s cluster. The K8s distribution can be upstream or provided by a vendor. Since it is a stateless application, it is capable of scaling horizontally utilizing K8s constructs / policies.
The resource requirements for Bridge is specified below:
For POC or testing purposes, non-HA configuration can be used, which requires the following resources:
- 1 compute node (Bare metal or a VM), with minimum of following resources:
- 32 vCPUs
- 64 GB RAM
- 500 GB HDD (preferably SSD)
- OS: Ubuntu 22.04
- Infrastructure: On-Prem VM / Baremetal Server
- Kubernetes Version: >=1.27.X
For production deployment, HA configuration of Bridge is recommended, which requires the following resources:
- 3-compute node cluster, with aggregate resources as follows:
- 64 vCPUs
- 128 GB RAM
- 1 TB HDD (preferably SSD)
- OS: Ubuntu 22.04
- Infrastructure: On-Prem VMs / Baremetal Servers
- Kubernetes Version: >=1.27.X
If additional levels of availability are required such as protection against disaster recovery, please contact Armada.
There may be additional requirements for the Management nodes, depending on other optional components (which are not part of the base Bridge functionality) that may need to be included, such as Billing software and so on.
Flexible Deployment Models for Different Business Needs
Enterprises and cloud providers require different levels of operational control over AI infrastructure. The RA supports multiple deployment models:
- Hosted Service / SaaS: A fully managed Bridge instance with continuous support and operational oversight.
- White-Label Platform: Enterprises can deploy an Bridge as their own branded Bridge, using software licensing approach.
- License-Based Model: Organizations can deploy and manage Bridge instance using a traditional software licensing approach.
Deployment of other optional components
There may be additional components that are required for the operation. In such cases, they need to be deployed as per the requirement from the specific vendor. This includes the following:
- NVIDIA’s BCM (Base Command Manager), which may be optionally used by Bridge for hardware provisioning and management. There needs to be one instance of a BCM cluster that should be installed, which will be used by Bridge. Please refer to the BCM documentation for the deployment requirements of BCM in the Management cluster. Once it is deployed, the end points of the BCM cluster need to be configured in Bridge. Redfish based provisioning is already supported and alternatives to BCM may also be supported in the future.
- It is possible that the Tenants onboarded by the NCP need to integrate with their LDAP/Active Directory. Each onboarded tenant may already have an existing identity provider (IdP) within their organization. To support Single Sign-On (SSO) and ensure a seamless user experience, Bridge implements identity federation. This will allow tenants to use their existing identity systems (such as Office 365 with Azure AD, Google Workspace, or Keycloak's OpenID Connect) for authenticating their users. Please contact Armada support for details.
- Monetize 360 (M360) Billing Software is optionally packaged with Bridge for Billing and Payment processing. The M360 software needs to be deployed in the same K8s cluster where Bridge is to be deployed, and the Service end-points of M360 needs to be configured in Bridge as part of the deployment. The deployment of M360 will require additional resources. Please contact Armada or M360 support for details. Alternatives to M360 or a BSS system already in use by the customer can also be supported. Please contact Armada for details.
- Other software components such as Backup/Recovery may be included in the deployment. The required components need to be installed along with Bridge. Please contact Armada support for details.
User personas and roles
On-demand multi-tenancy platforms supporting various use cases like offering the underlying infra as BMs, VMs, PaaS, model-as-a-service to enterprises and end customers require a rich user hierarchy with RBAC to use the platform with maximum flexibility.
To address this, Bridge supports the user hierarchy as depicted below:
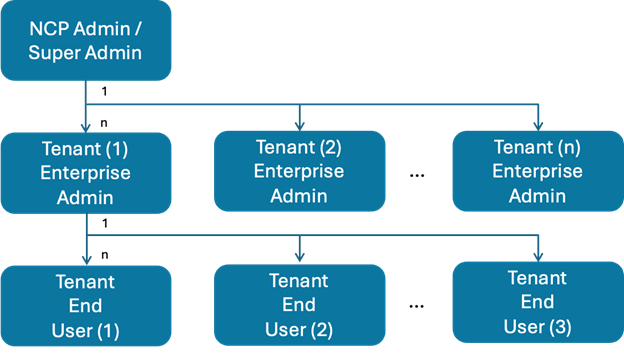 Figure 2: Bridge User Personas
Figure 2: Bridge User Personas
The user personas are:
- NCP Admin / Super Admin: An NCP / AI cloud provider persona owning the entire AI infrastructure. The NCP admin also manages tenants, instance flavors, OS artifacts, observability, and faults.
- Tenant Enterprise Admin: Admin persona from an enterprise to which the NCP / AI cloud provider has rented the infra or a service. This persona is responsible for the Tenants’ user management, resource usage, quota management, Billing, and more. There is one Tenant Admin for each Tenant.
- Tenant End User: The end user consuming the infra / service. The tenant end user manages their specific instances and has full observability for those instances.
Bridge provides granular RBAC to be configured by user personas above.
The relationship between user personas and various cloud services will be explained in the next section.
Bridge RA blueprint
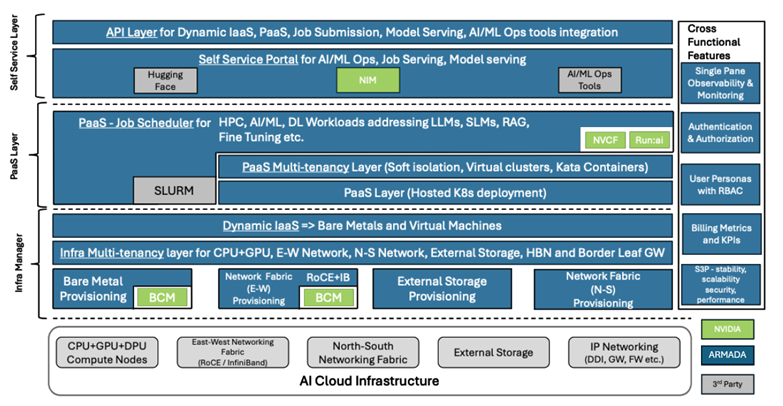
Figure 3: Bridge Reference Architecture
The above figure illustrates the Reference Architecture blueprint that NCPs and AI Cloud Providers can implement to offer their AI infrastructure to enterprises and end users in various forms, including IaaS, PaaS, and Model-as-a-service .
When deploying this RA, NCPs, and AI Cloud Providers have the flexibility to utilize the out-of-the-box capabilities of Bridge and integrate existing components from NVIDIA or other third-party providers, as needed.
The AI cloud infrastructure managed by Bridge includes:
- Compute nodes with NVIDIA GPUs (e.g., H100, H200, A100, L40S, etc.).
- East-West Networking Fabric with both Ethernet-based RoCE and InfiniBand (IB) switches.
- North-South Networking Fabric, ensuring connectivity to HPS and external networks.
- External high-performance and/or object storage.
- IP networking components (e.g., gateways, routers, etc.).
NVIDIA provides a set of Reference Architecture (NCP RA, Telco NCP RA, SpectrumX RA) specifications to achieve optimal GPU throughput for compute-intensive AI workloads and offers recommendations for implementing multi-tenancy. Bridge complies with NVIDIA’s RA specifications and automates all necessary steps to achieve this. Bridge RA is structured into four key layers: Infra Manager, PaaS Layer, Self-Service Layer, and Cross-Functional Features. The capabilities within these layers can be accessed via both API and GUI.
Infra Manager
Bridge Infra manager provides three main capabilities:
- Provisioning Layer: This layer performs Day 0 / Day 1 / Day 2 configurations of the underlying GPU cloud. For provisioning of bare metal compute nodes and the network switches, NVIDIA provides Base Command Manager (BCM). Bridge integrates with BCM or natively with Redfish to implement this layer.
- Infra Multi-tenancy Layer: This layer provides “converged” multi-tenancy capabilities to tenants encompassing CPU, GPU, E-W Network (for isolated communication between GPUs), N-S Network (for isolated communication with external storage and in-band management of GPU compute nodes), isolation within a single physical host using Host Based Networking (HBN) and finally edge router / gateway configurations as per tenant policies for external network connectivity.
- Dynamic IaaS: This layer provides functionality to dynamically allocate, de-allocate, provision Bare Metal nodes and to create, delete Virtual Machine instances – with configurable OS flavors.
Different persona consume the Infra Manager layer in different ways:
NCP Admin (Super Admin):
- Discover compute nodes and switches
- Validate discovered infra against the original intent/planned deployment
- Initiate automated underlay configuration
- Define OS flavors and populate them in the catalog
- Create Tenant Enterprise accounts
- Create / Invite Tenant admin user accounts
- Observe and monitor the entire AI cloud infra
- Define RBAC for tenant account
- Define quotas for tenant account
- Specify billing parameters
- Set FinOps alerts, enable / disable access to enterprise users
Tenant Admin:
- Create end users under tenant
- Define RBAC for end user accounts
- Define quotas for end user account
- Provision BM instances with desired OS flavor (Optional)
- Create VMs with desired flavors for tenant org users (Optional)
- Observability and monitoring of the AI cloud infra allocated to enterprise org
- Set FinOps alerts, enable / disable access to end users
- Billing interface for the Tenant
Tenant End User:
- Provision BM instances with desired OS flavor
- Create VMs with desired flavors, and manage their life cycle
- Create, manage (mount, unmount, delete etc.) storage instances
- Observability and monitoring of end user resources
Apart from enabling the tenants to consume infrastructure, Infra Manager also supports registering a set of compute resources with Lepton Cloud for monetizing unused capacity. Bridge securely isolates these compute resources from the rest of deployment before enabling it to be managed by Lepton cloud.
PaaS Layer
The PaaS layer needs to support a diverse set of AI/ML workloads, such as:
- Large language model training, inference, distilling, fine tuning, RAG
- Small language model training, inference
- Deep learning training
- HPC workloads
These workloads require different underlying platform capabilities. For example, HPC needs physical / virtualized compute clusters, while others need container orchestration tools like Kubernetes. There is no one-size-fits-all solution for providing a unified PaaS layer that is capable of supporting all such diverse workloads.3 Additionally, this layer also needs to be offered in a multi-tenant manner and in synchronization with the underlying infra components. Finally, the solution should also ensure optimum GPU utilization.
Bridge address these aspects by providing a PaaS layer with following capabilities:
- Create / Scale / Delete Kubernetes clusters using the underlying BM or VM compute instances
- Multiple Kubernetes distributions - Upstream K8s, RedHat Openshift, SuSE Rancher - are supported, and other distributions can be integrated easily due to the open nature of Bridge architecture.
- Native job scheduler with common interface for different types of job submission
- PaaS capabilities with underlay infra comprising both bare metal / virtualized compute nodes and K8s clusters
- Support for both containerized and non-containerized workloads
- Dynamic autoscaling of AI/ML workloads within and across clusters, based on GPU utilization
- Auto scale-in and scale-out of Kubernetes clusters by allocating and de-allocating GPU compute nodes
- Registering Kubernetes cluster with NVIDIA Cloud Functions (NVCF): GPUaaS providers/NCPs need to maximize the utilization of their GPUs to get the best return-on-investment. The NVIDIA Cloud Functions (NVCF) product is a mechanism to do so. NVCF allows NCPs to sell their unused capacity to pre-approved users as spot instances. From a technology point of view, the NCP needs to register a GPU based Kubernetes cluster that scales dynamically depending on the number of unused GPUs at any given moment in time. For example, there may only be 2 GPUs available at 2PM, but 200 GPUs available at 2AM. The Kubernetes cluster registered with NVCF needs to scale dynamically to accommodate these unused cycles. In this case, the cluster(s) are fully isolated from other tenants/workloads and scaled-out/in which allows the NCPs/GPUaaS providers to monetize their excess GPU capacity. Bridge provides usage metrics for these clusters that are registered with NVCF, to enable the billing process.
- Supporting 3rd party Job Schedulers: Bridge PaaS layer is also capable of utilizing 3rd party job schedulers like Run:ai and SLURM, based on the NCP / AI Cloud provider preferences. Run:AI is an AI/ML workload orchestration platform built on Kubernetes, providing dynamic GPU allocation, fractional GPU sharing, job queue management, and priority-based scheduling to maximize GPU utilization across multiple users and workloads. By integrating with Run:AI, Bridge enables organizations to take advantage of Run:AI's scheduling features while maintaining full control over resource allocation and multi-tenancy through Armada's Bridge-native capabilities. Additionally, Bridge provides fine-grained RBAC, tenant isolation, and a unified observability layer, allowing seamless orchestration of AI jobs while ensuring efficient GPU utilization, workload prioritization, and policy enforcement.
Different personas consume the PaaS layer in different ways:
In this scenario, the NCP Admin (Super Admin) does not have any role to play since their responsibility is to provide isolated infrastructure.
Tenant Admin:
- Create and manage clusters (add / remove nodes) comprising BM / virtualized compute nodes
- Create and manage Kubernetes clusters with multiple master and worker nodes (add / remove nodes)
- Define cluster wide policies
- Create / Invite end users
- Provision external storage for the clusters
- Define policies and quota for end users
- Observe and monitor the clusters
- Specify billing parameters
- Set FinOps alerts, enable / disable access to enterprise users
Tenant End User:
- Access PaaS resources
- Submit HPC, AI/ML custom jobs / workloads
- Monitor job status / workloads
Self-service Layer
The purpose of the self-service layer is to offer a set of pre-integrated ready to use LLMs and Inferencing services which could be selected from a catalog and then easily consumed. These models could then be fine-tuned, distilled, or deployed for production use cases. The self-service layer is also used to submit jobs (see above) and explicitly instantiate GPU resources.
For model serving, Bridge integrates with several external 3rd party tools / repositories and provides end users with a simplified interface to select a model, provide custom data sets and then submit the same to underlying PaaS layer for provisioning / scheduling.
As part of this feature, Bridge integrates with NVIDIA NIM (NVIDIA Inference Microservices), enabling seamless deployment and management of AI models. NVIDIA NIM provides containerized AI inference microservices that allow enterprises to deploy and serve models efficiently across NVIDIA GPUs in on-prem, cloud, and hybrid environments. It offers pre-built, accelerated AI models for various tasks, including LLM inference, speech recognition, vision AI, and generative AI. Through Bridge, users can seamlessly access and deploy NIM-powered models, integrate them into AI pipelines, and manage inference workloads with API-driven orchestration, and built-in observability. This integration simplifies AI model deployment while ensuring high performance and enterprise-grade scalability for inference-as-a-service offerings.
The integration with newer AI/ML model repositories, LLM models and AI/ML Ops tools is an ongoing activity, and the catalog is being constantly enriched. Please refer to the section related to 3rd party integrations further below, where a comprehensive list of existing model repositories and tools is provided.
Different personas consume the Self-service layer in different ways:
Similar to the PaaS layer, only the two user personas consume this layer.
Tenant Admin:
- Maintain LLM catalog (add, update, delete)
- Manage integrations with model repositories (add, update, delete)
- Specify billing parameters
- Create / Invite end users
- Observe and monitor all end user resources
- Set FinOps alerts, enable / disable access to end users
Tenant End User:
- Select and consume AI/ML service
- Submit / view job outputs
- Create explicit GPU resources
- Monitor usage
Cross Functional Features
These features span all the layers of the RA and are essential to provide a production ready platform. The components in this layer are:
- Single pane observability and monitoring: This enables each persona, based on their assigned privileges, to monitor the health of the infra and software components.
- Authentication and Authorization: Provides several authentication and authorization mechanisms such as LDAP, OAUTH2, MFA, AD etc. It also supports integration with multiple 3rd party IDM components.
- RBAC: Fine grained RBAC with configurability to assign specific privileges to user personas.
- Billing metrics & KPIs: Usage metrics of all tenant users are persisted and made available through multiple mechanisms such as CSV files, API invocation, dashboards etc. This helps for easy integration with the NCP / AI cloud providers billing system. As indicated above, M360 billing is offered as an optional component fully integrated with Bridge.
- S3P, logging, and audit trail: S3P refers to stability, scalability, security, and performance. Bridge is architected and tested for supporting all the major industry standard S3P practices. Bridge also logs all the user activities and supports audit trail for standard security compliance.
North Bound APIs
Bridge provides North Bound APIs to consume extensive set of product functionalities summarized as under:
- IaaS: BM, VM allocation and Lifecycle management
- PaaS: Cluster Lifecycle management
- Job submission
- Model serving
- Integration with various AI/ML tools
- Billing KPIs
- Performance metrics
- Authentication and Authorization
The APIs are constantly being enriched to provide more flexibility to end users.
Setting up a multi-tenant infrastructure
NCPs and AI Cloud Providers need to plan and design their AI cloud infrastructure based on their service offerings. Once all the hardware components are deployed physically in the data center, activities such as day 0 provisioning of bare metal servers, setting up the underlay network etc. typically follow. Bridge automates all these activities such as day 0 and day 1 discovery and provisioning of complete Data Centre topology that includes GPU compute nodes, network switches and storage nodes.
This section discusses the technical aspects of setting up the infrastructure so that it can be consumed by multiple tenants in an isolated manner. By isolation, we mean hard isolation that is equivalent to physical isolation. We exclude Kubernetes style soft isolation.
To start, Bridge performs infrastructure discovery and configuration, in a sequence of steps:
- Network & GPU Fabric Discovery: The NCP admin can initiate the discovery process for a multi-tier network and GPU fabric, enabling centralized management.
- Fabric Components: The fabric includes Ethernet switches, InfiniBand switches, and a Subnet Manager (UFM), which are essential for configuring and managing network connectivity.
- Automated Infrastructure Discovery: Once triggered, the discovery process discovers all the GPU compute nodes, identifies and maps the GPU compute nodes to network switch ports and builds a topology providing a comprehensive view of the infrastructure.
- Multi-tenancy configurations: This involves configuring the CPU and GPU compute nodes, network fabric comprising Ethernet / InfiniBand and external storage for simultaneous usage by multiple tenants ensuring strict isolation.
- Centralized Management: After discovery, the entire infrastructure—including network switches and GPU fabric—can be orchestrated and managed by Armada,ml Bridge platform, ensuring streamlined operations and automation.
Further sub-sections detail all the above activities for setting up a multi-tenant AI cloud infrastructure.
Hardware Provisioning
The Hardware provisioning of the underlying compute resources involves multiple steps. This assumes that the provisioning is done directly using Bridge. If other provisioning tools (such as NVIDIA BCM) are used, the following steps will not be needed.
-
Bare-Metal Provisioning via Redfish:
- Bridge leverages Redfish to communicate with the server's Baseboard Management Controller (BMC), allowing for full control over server hardware.
- Redfish enables tasks like power management, hardware configuration, and eventually operating system (OS) installation on bare-metal servers.
-
Integration with MaaS (Metal as a Service):
- Internally, Bridge integrates with MaaS for OS provisioning. MaaS is an open-source tool designed for automating the provisioning of physical servers in a datacenter.
- While Redfish handles the hardware provisioning, MaaS takes care of the OS installation, enabling seamless automation of OS deployment on bare-metal machines once they are powered on and initialized.
-
Custom OS Image Management:
- The NCP Admin (Network Control Panel Admin) is responsible for managing custom operating system images within Bridge UI. These images can be pre-configured OS environments tailored for specific tenant needs.
- The admin can upload or configure OS images, making them available for tenants to use when provisioning new machines.
-
Provisioning and De-Provisioning Flows:
Both provisioning and de-provisioning flows are supported:
- Provisioning involves installing and configuring the hardware and OS according to tenant specifications.
- De-Provisioning allows Bridge to securely shut down and wipe the hardware, making it available for future use. This may involve wiping the storage, resetting hardware settings, and returning the server to a "bare" state.
Once the provisioning is done, the tenant users can request bare-metal servers via Bridge UI, selecting from the custom OS images that the admin has prepared. Once the tenant selects an OS image and initiates the provisioning, Bridge uses Redfish to manage the underlying hardware, while MaaS takes over the OS installation.
In few deployment scenarios, where NCPs prefer NVIDIA Base Command Manager (BCM) for low level infrastructure provisioning, Bridge integrates with BCM for offering the above functionalities though a single pane of glass. Please refer to figure 3 (Armada Reference Architecture) that depicts BCM integration with Bridge.
Finally, Bridge also supports day 2 management activities involving OS upgrades, applying patches etc.
Network Underlay Configuration
All leaf switches in the tier 2 / tier 3 topology have L3 connectivity. To establish L2 subnets and L2 adjacency for each tenant while enabling L3 networking, an EVPN BGP-based overlay is deployed. This setup requires configuring the BGP underlay across all switches in the fabric. The diagram below illustrates how Bridge configures the underlying network for a Spectrum-X-based fabric.
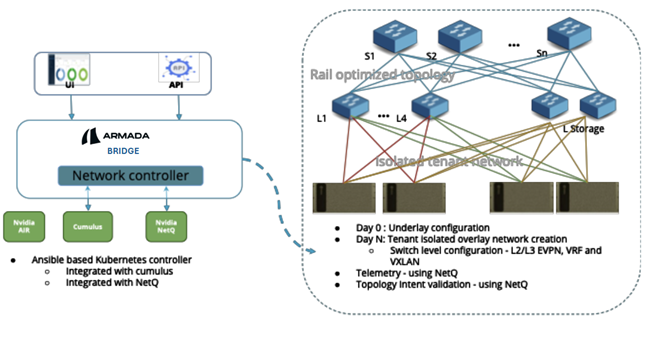
Figure 4: NVIDIA SpectrumX Controller by Bridge
The Bridge Spectrum-X Network Controller is a comprehensive solution designed to manage and optimize network configurations in GPU-accelerated environments. Key features and capabilities include:
-
Ansible-based Kubernetes Controller:
- Reconciles underlay and overlay network configurations.
- Addresses configuration drift by managing out-of-band events such as configuration changes, switch replacements, and link failures.
-
NVIDIA Spectrum-X Reference Architecture Compliance4:
- Compliant with Spectrum-X RA v1.1.0.
- Enables rail-optimized topology configurations for East-West and North-South network flows.
- Supports advanced networking features:
- IP Addressing: Configures IPs at compute-leaf and leaf-spine levels as per NVIDIA RA recommendations.
- RoCE and QoS: Manages RDMA and Quality of Service settings for optimal performance.
- BGP Underlay Configuration: Provides scalable Layer 3 networking.
- VXLAN-EVPN: Delivers per-tenant virtualized networking at Layer 2 and Layer 3.
-
Topology Intent Validation:
- Offers a user interface (UI) for validating topology configurations.
- Supports discovery and auto-configuration for scaling network topologies.
-
NetQ Integration:
- Integrates with the NVIDIA NetQ Server API for telemetry and event subscription, enhancing operational visibility.
-
Closed-Loop and Open-Loop Operations:
- Closed-Loop: Works with the Bridge event monitoring framework to enable auto-configuration based on real-time events.
- Open-Loop: Reports events and notifications directly to the Bridge UI, providing administrators with actionable insights and control.
Tenant Network Configuration
To ensure tenant-level isolation in the compute network, different mechanisms are used depending on the underlying fabric. The configuration ensures multi-tenancy, security, and seamless integration between different network types while maintaining high performance and scalability.
Compute Network Isolation
-
Ethernet Network:
- Each tenant is assigned a unique VXLAN ID.
- VXLANs are extended across the fabric using BGP EVPN, providing L2 adjacency across L3 fabric.
- Each tenant's compute VXLAN ID is mapped to the corresponding tenant's converged VXLAN ID, ensuring seamless integration with the converged network.
-
InfiniBand Network:
- Each tenant is assigned a unique Partition Key (PKEY) to enforce network isolation.
- The tenant’s PKEY is mapped to a corresponding tenant-specific converged VLAN ID, enabling interoperability between InfiniBand and Ethernet segments.
Converged Network & Isolation
The Converged Network integrates multiple traffic types, including:
- Storage Traffic: Facilitates high-performance access to storage backends such as VAST, DDN, Weka, or any other storage solution.
- In-band Management: Used for managing compute and storage resources within the infrastructure.
- External Connectivity: Enables communication with external networks and cloud providers.
For Converged Network Isolation:
- Similar to compute network isolation, per-tenant VXLANs are leveraged.
- BGP EVPN is used to propagate VXLAN mappings across the network, ensuring secure tenant-specific isolation across the entire converged network.
This approach provides multi-tenancy, security, and seamless integration between different network types while maintaining high performance and scalability.
Refer to figure below for a detailed illustration of the tenant network configuration and isolation mechanisms.
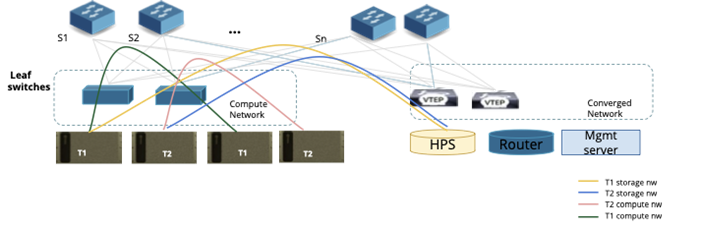
Figure 5: Fabric Level isolation for Tenants
Tenant Network Isolation Configuration flow - Ethernet
The following example illustrates how network provisioning occurs in a Single Scalable Unit (SU) topology consisting of Leaf Switches and Compute Nodes.
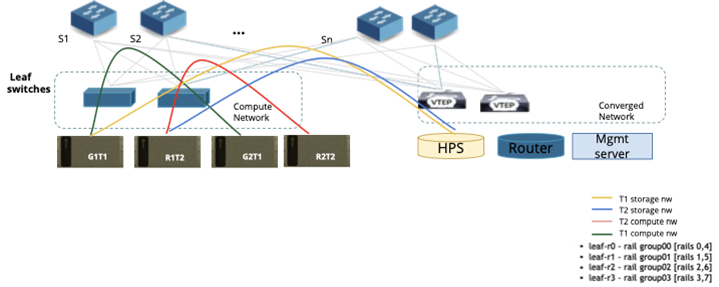
Figure 6: Fabric Level isolation for Tenants
Step 1: Underlay Network Configuration
-
NCP Admin triggers underlay configuration:
- This action sets up the BGP EVPN control plane across the network fabric, enabling dynamic route advertisement and tenant network isolation.
- Leaf switches are configured with BGP sessions to exchange VXLAN-based overlay routes.
Step 2: Tenant Creation (see Figure 6)
-
NCP Admin creates two tenants: T1 and T2.
-
Virtual Routing and Forwarding (VRF) instances are assigned to each tenant:
-
Tenant T1:
- Compute Traffic → VRF Green
- Storage Traffic → VRF Yellow
-
Tenant T2:
- Compute Traffic → VRF Red
- Storage Traffic → VRF Blue
-
-
No actual configuration is applied to the switches yet. These VRFs are placeholders until workloads are allocated.
Step 3: Compute Allocation for Tenant T1
- Tenant T1 requests two compute nodes.
- Bridge allocates Compute Nodes G1T1 and G2T1.
- Network setup for T1:
- Rail group switch ports (used for compute-to-network connectivity) on all leaf switches are mapped to VRF Green.
- In-band management ports on leaf switches are mapped to VRF Yellow.
- Route exchange configuration:
- Routes between VRF Yellow and Default Storage VRF are exchanged, enabling storage access.
- Routes between VRF Yellow and External Network VRF are exchanged, allowing external connectivity.
- Public IP addresses for G1T1 and G2T1 are assigned, along with access credentials provided to Tenant T1.
Step 4: Compute Allocation for Tenant T2
- Tenant T2 requests two compute nodes.
- Bridge allocates Compute Nodes R1T2 and R2T2.
- Network setup for T2:
- Rail group switch ports on all four leaf switches are mapped to VRF Red.
- In-band management ports on leaf switches are mapped to VRF Blue.
- Route exchange configuration:
- Routes between VRF Blue and Default Storage VRF are exchanged, enabling storage access.
- Routes between VRF Blue and External Network VRF are exchanged, allowing external connectivity.
- Public IP addresses for R1T2 and R2T2 are assigned, along with access credentials provided to Tenant T2.
Tenants may also want to create multiple VPCs, subnets and security groups and assign various resources to specific VPCs. This would enable them to define network segmentation within their allocated resources. The network isolation for every VPC would be done in the similar mechanism as explained above.
Tenant Network Isolation Configuration flow - InfiniBand
For managing the InfiniBand network fabric, the network is configured using the Unified Fabric Manager (UFM). Bridge is tightly integrated with UFM, enabling automated network discovery and tenant-based network isolation.
Network Discovery & Tenant Configuration
-
InfiniBand Fabric Discovery
- During the network discovery process, the UFM controller within Bridge automatically discovers the entire InfiniBand fabric through UFM.
- This process identifies all switches, compute nodes, and links, ensuring visibility into the topology.
-
Per-Tenant PKEY Creation
- When a new tenant is created in Bridge, UFM dynamically provisions a unique Partition Key (PKEY) for that tenant.
- PKEYs act as isolated virtual networks, ensuring that traffic is restricted to members within the same tenant.
Compute Allocation & Network Mapping
- Network Interface Mapping
- When a compute instance (bare metal or virtual machine) is allocated to a tenant, the InfiniBand controller in Bridge assigns the compute node’s network interface GUIDs (Globally Unique Identifiers) to the corresponding tenant’s PKEY.
- This ensures that the allocated compute resources can communicate securely within the tenant’s isolated InfiniBand network.
By leveraging UFM integration, Bridge provides a fully automated, tenant-aware InfiniBand network configuration, ensuring seamless connectivity, isolation, and efficient resource utilization across the fabric.
For the InfiniBand network fabric, the network is configured through the Unified fabric manager (UFM). Bridge has integration with the UFM.
- During the network discovery flow, the UFM controller in Bridge discovers the InfiniBand fabric via the UFM.
- The per tenant PKEYS are created via the UFM, when the tenants are created.
- During the compute allocation the InfiniBand controller in Bridge, performs the required mapping of the network interface GUIDs to the tenant PKEYS.
High performance Storage Integration
Bridge integrates with storage solutions from vendors such as VAST, Weka.io, and DDN. It connects to these storage appliances, enabling the management and allocation of storage resources in a multi-tenant environment.
- Creation of Tenant-Specific Storage Networks: At the fabric level, Bridge ensures that each tenant is isolated with its own dedicated storage network.
- Tenant Configuration on Storage Appliance Management Node: Bridge configures the tenant entity within the storage appliance’s management node. This means the storage appliance is aware of the new tenant and can apply any tenant-specific configurations, such as permissions, volume sizes, and access policies. By configuring the tenant entity, Bridge ensures that each tenant has the appropriate access and can manage their allocated resources within the storage system.
- UI Flow for Storage Allocation: Through a flow in Bridge UI, tenants can allocate storage volumes from the high-performance storage appliances (HPS). This could include tasks like choosing the volume size, performance characteristics, and other properties based on the storage provider's capabilities. After allocation, tenants can mount the storage volumes on their compute nodes (e.g., virtual machines, bare-metal servers, or Kubernetes clusters). This allows the compute resources to access the storage for data processing or application needs.
- De-Allocation and Cleanup of Storage Volumes: When a tenant no longer needs a particular storage volume, they can de-allocate it via Bridge UI. During the de-allocation process, Bridge ensures that the volume is securely cleaned up such that the data cannot be recovered.
External Network Connectivity
There needs to be external connectivity to the Tenant network, such that the tenant users can access the resources (Bare metal servers, VMs, K8s Clusters) from external networks. Bridge facilitates this, by working with the NCP or the GPUaaS provider IT team, and configuring the Border Leaf switches, and other Networking Equipment (Routers, Firewalls) in their network. Tenants could create separate VPCs and security groups for resources that need access to external gateway.
This process involves the following steps:
-
Bridge configures North-South Network with L3 EVPN Isolation and External Connectivity
-
Running MP-BGP EVPN Inside Fabric:
- Distributes internal VXLAN routes dynamically
- Automatically imports external IPv4/IPv6 routes into the EVPN domain
-
Configuring Border Leaf nodes:
- The border leaf nodes are the connection points of a fabric network to the outside
- They run dual protocols:
- MP-BGP EVPN for internal VXLAN communication
- eBGP (or IGP) for external routing with upstream routers
- Route Exchange:
- External routes (e.g., internet default routes) are advertised to VTEPs via EVPN
- Internal EVPN routes are translated to IPv4/IPv6 unicast and advertised externally
-
Providing Multi-tenancy:
- Tenant-specific routing using VRFs on the border leaf
- VRF-lite used on external routers to maintain tenant isolation
-
Router and Firewall VPC and security group related configurations will depend on the vendor capabilities
Refer to figure below for a detailed illustration of configuration of external connectivity in a multi-tenant set-up.
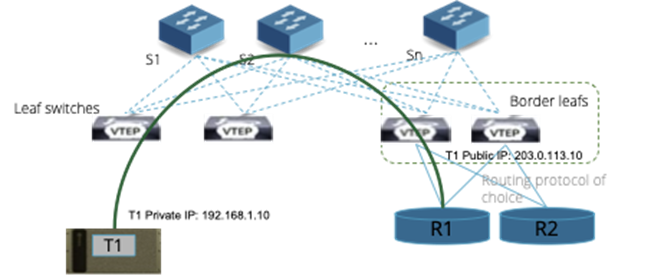
Figure 7: External Network Connectivity for Tenants
A Static NAT configuration is established for mapping the Public IPs provided by the Internet Service Providers to the NCP/GPUaaS providers. This configuration will involve working with the IT teams of the NCPs and providing the required automation as part of Bridge.
The process involves the following steps:
- External IPs are provided by the ISP
- The border leaf maps private IPs to public IPs for inbound and outbound traffic
- Public IPs are reused efficiently while maintaining internal tenant isolation
Example flow for inbound traffic with public IP:
A VM in Tenant 1 (192.168.1.10) hosts a web server and should be reachable using a public IP (e.g., 203.0.113.10).
Flow:
-
Public IP Assignment:
- The border leaf is configured to map 203.0.113.10 (public) to 192.168.1.10 (private) using static NAT
-
Inbound Request:
- A client from the internet sends a request to 203.0.113.10
- The external router forwards this traffic to the border leaf
-
Border Leaf Translation:
- The border leaf translates 203.0.113.10 to 192.168.1.10 and forwards the traffic to Tenant 1’s VRF
- VXLAN routing delivers the packet to the web server VM
-
Response:
- The web server responds to the client
- The border leaf translates the private source IP (192.168.1.10) back to the public IP (203.0.113.10) for outbound traffic
BMaaS, VMaaS and PaaS consumption by tenants
Any “as-a-service” offering needs to fundamentally support “multi-tenancy” at its core. The same physical infrastructure needs to be logically sliced and isolated for every tenant without compromising on the throughput and latency requirements of the tenant workloads.
Bare Metal-as-a-service (BMaaS) could be offered for scenarios where the entire GPU compute nodes need to be allocated to the tenants. Virtual Machine as-a-service (VMaaS) could be offered when tenants need smaller number of GPUs than the available GPUs on a single node. Platform as-a-service (PaaS) could be offered when tenants are more focused on their jobs and workloads and need a platform layer which is capable of managing these while optimizing on the GPUs.
For these scenarios, isolation of infrastructure needs to span across all the layers encompassing host hardware (CPU & GPU), platform software (e.g. Container as a Service i.e. CaaS), storage and networking devices (Switches & Routers).
This section explains multi-tenancy options for each of the layers and based on the use cases and end user offerings, NCPs / AI cloud providers could choose a suitable option.
Hardware Infra isolation
The isolation of the infrastructure needs to work at different levels, and work together, to provide seamless experience in the multi-tenant environment.
Bridge provides strict isolation as follows:
CPU: Isolation of CPU for multiple tenants can be achieved by using either bare metal or virtualization5, mechanisms. These are the most popular and proven technologies that have been around for many years now. For those who can accept soft isolation, containerization is also an option.
GPU: GPU isolation is done at individual GPU level, as well as fractional GPU. The GPU level isolation is done by mapping the GPUs to the compute instances directly. For eg., in case of H100, each of the 8 GPUs in a single server (HGX) can be mapped (in a pass-through mode) to different Virtual Machine instances that are allocated to different tenants. Similarly, fractional GPU allocation is supported by using multi-instance GPUs (MIG) that are supported by NVIDIA in its Ampere GPUs onwards (A100, A30, H100, etc.). MIG creates independent GPU instances with separate compute, memory, and cache resources. Using MIGs, the same GPU is sliced into up to seven (7) instances that can be independently allocated to different tenant workloads.
IP/Ethernet network: The tenant traffic is isolated using VXLAN for data path and utilizing BGP-EVPN as control plane. Each tenant is assigned a unique VNI and VRF. See above for more details.
InfiniBand (IB) network: The tenant is assigned a unique PKEY for isolating the IB tenant traffic. This is done by interfacing with UFM (Unified Fabric Manager). See above for more details.
External Storage: Based on the storage vendor capabilities, a separate mount point is created for every tenant by utilizing storage vendor’s APIs. Isolation of network traffic for external storage access leverages the storage vendor capabilities. In case the vendor does not natively support multi-tenancy, Bridge uses network based isolation using VRFs.
Isolation at GPU Compute boundary
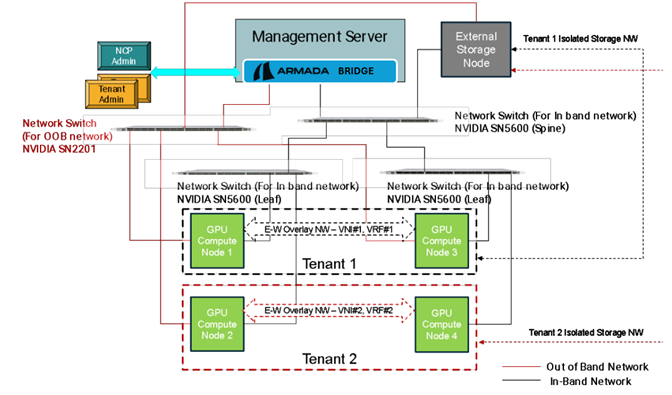
Figure 8: Compute/GPU isolation for servers
The above diagram represents a scenario where a tenant needs a set of bare metal servers to be allocated and hence there is no need for advanced CPU and GPU isolation. However, the network and external storage isolation needs to be configured based on the technologies stated above.
The above topology used for sample representation comprises of:
- Four GPU compute nodes
- One Management node hosting Bridge
- One external storage node
- Two leaf switches (NVIDIA SN5600)
- One spine switch (NVIDIA SN 5600)
- One OOB switch (NVIDIA SN2201)
GPU compute node 1 and GPU compute node 3 are part of Tenant 1. Similarly, GPU compute node 2 and GPU compute node 4 are part of Tenant 2. Each of the tenant GPU compute nodes are connected to separate leaf switches.
Using the isolation mechanisms stated above, CPU and GPU are isolated at the server boundary. Two VXLAN based overlay networks are created for each tenant. These overlay networks also extend to the common external storage device. Bridge automates isolation of the entire tenant path from compute, storage and network. Thus, effectively when a tenant user gets access to its compute nodes, all the switches are configured with an overlay network in place for respective tenants.
Isolation within a single node (HBN)
If the tenant user requires fewer GPUs than the available count of GPUs on one single node, it would require CPU, GPU and network isolation within a single node.
For compute requirements in such scenarios, Virtual Machine with GPU pass through is allocated to individual tenants. For network isolation, Host Based Networking (HBN) utilizing NVIDIA Bluefield-3 DPU is utilized to isolate the tenant traffic. HBN on BF3 DPU supports OVS based implementation of VXLAN / BGP-EVPN for isolation and thus this works in a transparent manner with ethernet networking fabric. Thus, individual tenants owning a complete bare metal node or a VM instance should be able to communicate between themselves using the common network isolation technique. In the absence of BF3 DPUs, the same functionality is implemented using host CPU resources, with associated performance implications.
Refer to figure below for a detailed illustration of HBN set-up on two physical nodes. HBN on each node creates another layer of overlay between compute node DPUs to achieve isolation between tenant VMs on different hosts.
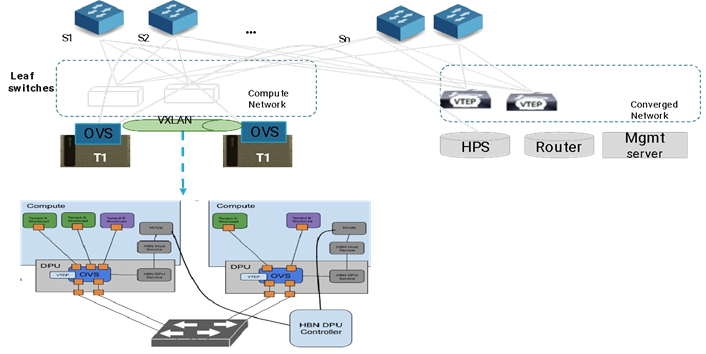
Figure 9: Host Based Networking
Tenant Traffic Isolation: Host-Based Networking (HBN) using NVIDIA BlueField-3 DPU ensures isolation of tenant traffic at the host level, enhancing security and performance.
OVS-Based VXLAN & BGP-EVPN: HBN on BlueField-3 DPU implements Open vSwitch (OVS)-based VXLAN and BGP-EVPN, providing scalable, multi-tenant isolation across the network fabric.
Seamless Ethernet Integration: The VXLAN/BGP-EVPN implementation on the DPU enables transparent operation with the existing Ethernet networking fabric, ensuring compatibility without major infrastructure changes.
Support for Both Bare Metal & VMs: HBN allows isolation of traffic for both bare metal servers and virtual machines, ensuring that tenants can securely communicate within their designated networks.
Standardized Isolation Mechanism: By leveraging HBN with VXLAN and BGP-EVPN, tenants benefit from a consistent, well-supported isolation strategy, reducing operational complexity and enhancing network security.
Below diagram depicts this scenario in a simplified deployment set-up to explain the isolation techniques.
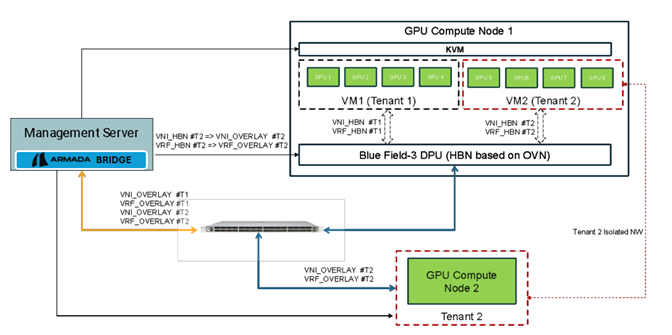
Figure 10: Compute/GPU isolation within a node
The simplified topology comprises of:
- Two GPU compute hosts
- Ethernet network for E-W and in-band management
- Management server hosting Bridge
In this example, Tenant 1 is requesting 4 GPUs and Tenant 2 is requesting two nodes, one with 4 GPUs and another with 8 GPUs. Bridge performs following automation to serve these resource allocation requests:
- For Tenant 1, spin up a VM with 4 GPUs allocated in a pass-through mode on GPU Compute Node 1.
- Utilize NVIDIA DPU based HBN on GPU Compute node 1 to create virtual VXLAN network for Tenant 1.
- For Tenant 2, allocate GPU Compute Node 2 for instance requiring 8 GPUs. Spin up a VM with 4 GPUs allocated in a pass-through mode on GPU Compute Node 1, for instance requiring 4 GPUs.
- Create and Configure VXLAN overlay for Tenant 2 on the switch and GPU Compute Node 2.
- Configure NVIDIA DPU based HBN on GPU Compute node 1 to create virtual VXLAN network for Tenant 2.
- Configure the DPU on GPU Compute Node 2 to add mapping between Tenant 2 virtual VXLAN and Overlay VXLAN network for Tenant 2. This ensures that traffic between VM2 and GPU Compute Node 2 is routed correctly.
PaaS isolation (K8s based)
The tenant isolation mechanisms for K8s based PaaS are summarized below.
Dedicated PaaS for tenants: For strict isolation requirements, a separate K8s cluster is provisioned on fully isolated VMs or Bare metal servers and allocated to a tenant. In this case, the underlying Bare Metal servers or VMs are also isolated for the tenant using the techniques described in hardware infra isolation section above. For scenarios where enterprises need significant GPU capacity where a set of bare metal compute nodes need to be allocated to the tenant, this isolation mechanism should be used. This is the default K8s clustering support provided by Bridge, since this provides the highest level of security for the tenants.
There are other mechanisms that provide soft isolation that can be supported by Bridge for specific use cases that do not require strict isolation. These include the following:
Kubernetes Namespace: This is the commonly used isolation technique natively supported by K8s. This is a soft isolation technique since tenant workloads share common K8s master and worker nodes and common K8s control plane components – e.g. API server and the operating system. For use cases where enterprises need to offer a common PaaS layer and isolate it for different orgs within the same enterprise or in the scenarios where the workloads could be trusted, Namespace based soft isolation techniques could be considered.
vCluster: This isolation technique is stronger than the Namespace based isolation but still uses the same worker nodes for all the tenants. Within each tenant’s namespace a virtual k8s cluster is deployed. vClusters run their own Kubernetes API server within a Namespace of the host cluster. This isolation technique could be considered when tenant users or enterprise org users require a logically isolated K8s cluster that can inherit the overall K8s cluster wide policies.
Maximizing ROI
A primary objective of Armada GPU Cloud Management System (Bridge) is to empower NVIDIA Cloud Providers (NCPs) to achieve the maximum possible ROI on their GPU hardware and software investments. While the preceding sections detailed how to transform static infrastructure into a dynamic, secure, multi-tenant platform, this section focuses on three key features that directly drive profitability and value creation.
Driving Maximum GPU Utilization through Virtualization and Oversubscription
A significant challenge in a multi-tenant environment is inefficient resource allocation. Tenants often request more GPUs than they need, leading to valuable hardware sitting idle while being allocated. Bridge addresses this directly with a two-pronged approach:
-
GPU Virtualization & Sharing: Our platform enables a single physical GPU to be partitioned into multiple smaller, isolated virtual GPUs. Using technologies like NVIDIA MIG and advanced time-slicing, an NCP can serve multiple smaller workloads (e.g., development, testing, small-scale inference) on a single powerful GPU, dramatically increasing its utilization rate from single digits to over 90%.
-
Intelligent Quotas & Oversubscription: Building on this, administrators can assign a flexible resource quota to each tenant. This allows tenants to dynamically allocate and de-allocate GPUs as needed, while ensuring they never exceed their overall limit. This model benefits both parties: tenants only pay for the resources they actively consume, and the NCP can safely oversubscribe the physical infrastructure—allocating more virtual resources than are physically present—based on statistical usage patterns, further maximizing the revenue potential of every single GPU.
-
Advanced Scheduling Engine: To enable this level of efficiency, Bridge is built upon a sophisticated scheduling foundation. It integrates with and extends the powerful open-source scheduler KAI (https://github.com/NVIDIA/KAI-Scheduler). This provides multiple scheduling policies, ensuring large, distributed jobs are placed on the most optimal hardware to minimize communication latency. This intelligent placement reduces resource fragmentation and is a critical enabler for the dynamic virtualization and oversubscription capabilities of the platform.
Moving Up the Value Chain from IaaS to AI PaaS
To transition from being a simple infrastructure provider to a high-value AI platform, NCPs must offer services that accelerate their tenants' entire AI lifecycle. Bridge provides the tools to build a rich Platform-as-a-Service (PaaS) offering:
-
Support for Traditional HPC & Research Workloads: Many customers in scientific computing and research institutions have existing workflows built around the Slurm Workload Manager. Bridge provides a "Slurm-as-a-Service" capability, allowing these tenants to run their existing Slurm jobs on the NCP's modern, GPU-accelerated cloud infrastructure without modification. This provides a seamless on-ramp for a valuable and extensive customer segment.
-
Turnkey MLOps Integration: The platform provides seamless integrations with the industry's most popular MLOps tools, such as Kubeflow, MLflow, and Airflow, via a robust API and pre-built Terraform providers.
-
Fine-Tuning-as-a-Service (FTaaS): Offer a simplified, UI-driven service for tenants to fine-tune popular open-source models (like Llama 3 or Mistral) on their private data.
-
Model-Inference-as-a-Service (MlaaS): Enable tenants to deploy their models as scalable, serverless endpoints. The platform handles the auto-scaling of GPUs in the background, allowing the NCP to offer a usage-based pricing model (e.g., per-token or per-API-call).
Monetizing Unused Capacity through Federated Marketplaces
Even in a well-managed cluster, there will be periods of unused capacity. Bridge allows NCPs to turn this idle hardware into a revenue stream.
- Secure Marketplace Integration: Our platform provides one-click integrations with third-party GPU marketplaces, such as NVIDIA Lepton AI and NVCF.
- Automated Provisioning & Security: Using the GUI, an administrator can securely partition a set of GPU nodes, isolate them from their primary tenant infrastructure, and register them with an external marketplace. When the capacity is no longer needed, it can be de-registered and returned to the internal pool with just a few clicks.
Summary
The On-Demand Multi-tenancy Reference Architecture (RA) addresses the core challenges faced by NVIDIA Cloud Partners (NCPs) and AI Cloud Providers in delivering a scalable, API-driven, multi-tenant AI infrastructure. This RA provides a unified approach to handling diverse compute, networking, storage, and PaaS requirements, ensuring seamless tenant onboarding, workload isolation, and dynamic resource provisioning. This ultimately results in a dramatically improved return-on-investment from the NCP.
Key Benefits of the RA
Optimizing GPU Utilization:
The RA optimizes GPU resource allocation through intelligent job scheduling, ensuring that a wide range of AI/ML workloads—such as LLM training, inference, fine-tuning, and RAG—are executed efficiently. Dynamic repurposing of GPU nodes enables cost-effective resource usage and prevents underutilization.
Simplified Operations & Automation:
A key advantage of this architecture is its ability to automate tenant onboarding, resource allocation, monitoring, and scaling, significantly reducing manual intervention. This leads to operational simplicity, enhanced observability, and easier management of AI workloads across multiple tenants.
A Comprehensive Multi-Tenancy Framework:
The RA integrates multi-tenancy across all infrastructure layers, including compute, networking, storage, and PaaS, ensuring hard tenant isolation and security. It eliminates fragmented implementations by enabling automated, best-fit isolation techniques for different workloads, whether using physical, virtual, or logical resource segmentation.
Support for Multiple Business Use Cases:
With the ability to extend service offerings from bare-metal GPU provisioning (IaaS) to Kubernetes-based model serving and AI PaaS, the RA supports a broad range of business models. This allows providers to scale seamlessly across static, on-demand, and serverless AI workloads.
Alignment with NVIDIA RA Guidelines:
The architecture is built in compliance with NVIDIA’s best practices, ensuring seamless compatibility with industry-leading AI/ML hardware, software stacks, and cloud infrastructure standards.
Extensibility & Integration with 3rd Party Tools:
The RA provides built-in job scheduling but remains highly extensible, allowing providers to integrate their preferred job schedulers like Run:AI or other custom solutions. Additionally, it supports seamless integration with external storage vendors, Kubernetes distributions, AI/ML tools, and model repositories such as Hugging Face and NVIDIA NIM.
By leveraging this comprehensive reference architecture, AI cloud providers can maximize efficiency, simplify AI infrastructure management, enhance GPU utilization, and deliver flexible, scalable, and cost-effective AI services.