Deploy Hugging Face Model
Overview
This guide walks you through deploying a Hugging Face model from Bridge model catalog. Hugging Face models are open-source models hosted on the Hugging Face Hub (e.g., Qwen/Qwen2.5-1.5B-Instruct, meta-llama/Llama-3). Bridge pulls the model weights from Hugging Face, serves the model on GPU infrastructure, and exposes it via an endpoint for inference.
This guide covers:
- Selecting a Hugging Face model from the catalog and starting deployment
- Configuring the model name, endpoint, GPU type and count, and rate limits
- Providing a Hugging Face token (if required)
- Monitoring deployment until the model is running
Prerequisites
- Tenant Admin access — You must log in as a Tenant Admin to deploy models from the catalog.
- Model catalog — The Hugging Face model you want to deploy must be available in Bridge model catalog. The Available Models tab lists all deployable models. If the model you need is not listed, contact your Bridge Super Administrator to add it.
- Endpoint — You may need to create or select an LLM endpoint before or during deployment.
- Hugging Face token — Some models (especially gated models) require a Hugging Face access token to download model weights. Have your token ready.
note
If you do not have a Hugging Face token, create one from https://huggingface.co/ — sign in or sign up, then create a token in your account settings.
Deploy Model
Step 1: Select Model
- Log in to Bridge as a Tenant Admin.
- In the left sidebar, open Models.
- Open the Available Models tab. All catalog models available for deployment are listed.
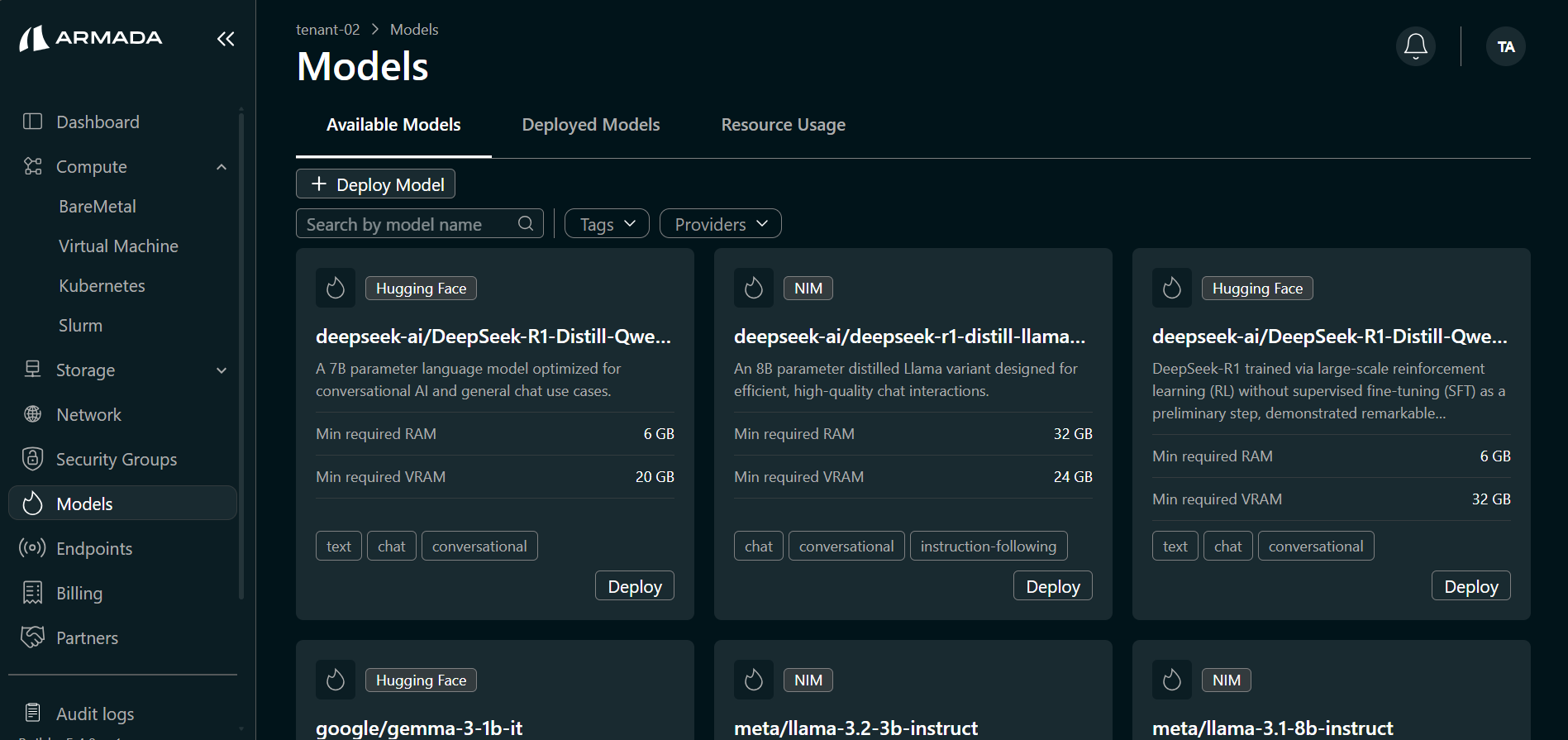
- Find the Hugging Face model you want to deploy (e.g., Qwen/Qwen2.5-1.5B-Instruct) and click Deploy.
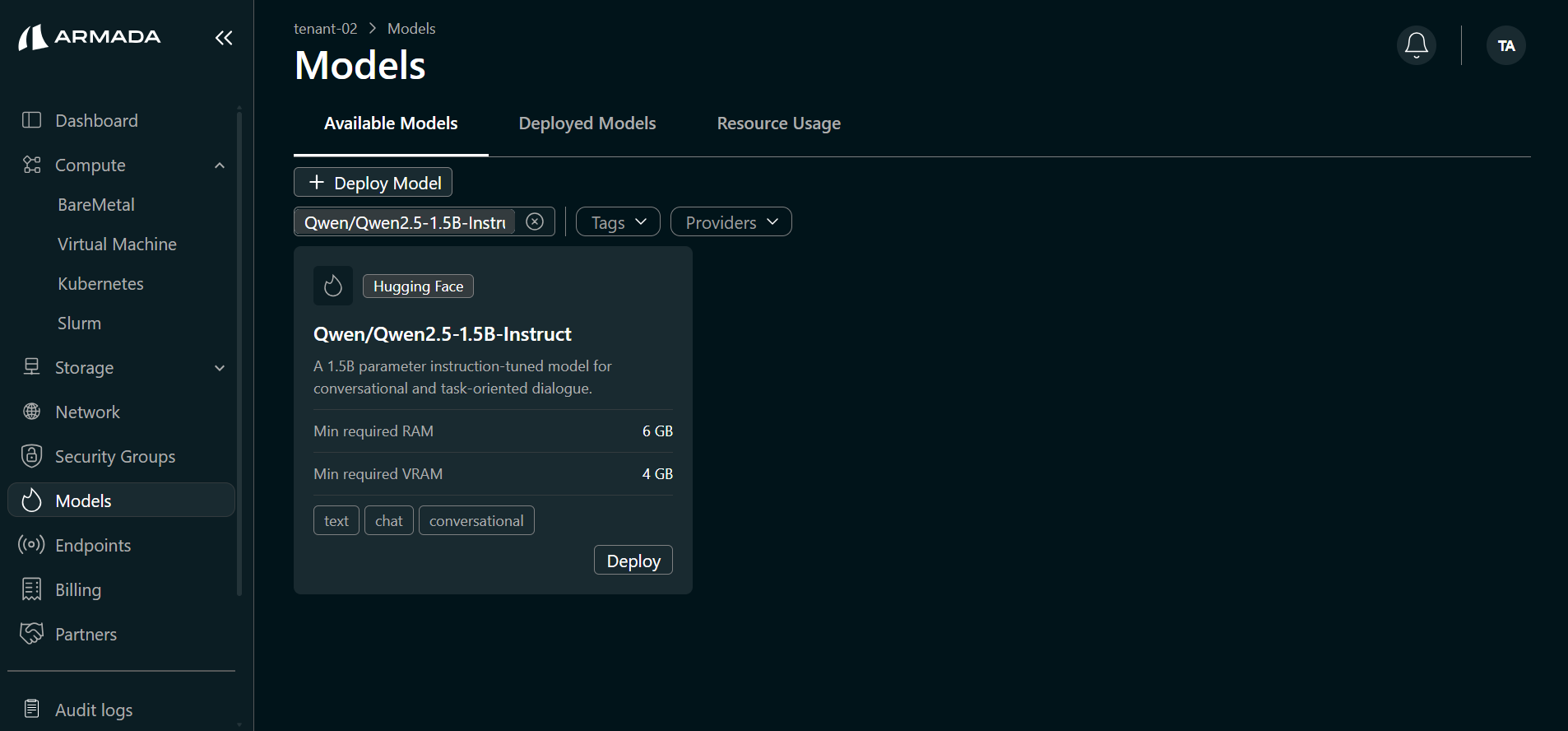
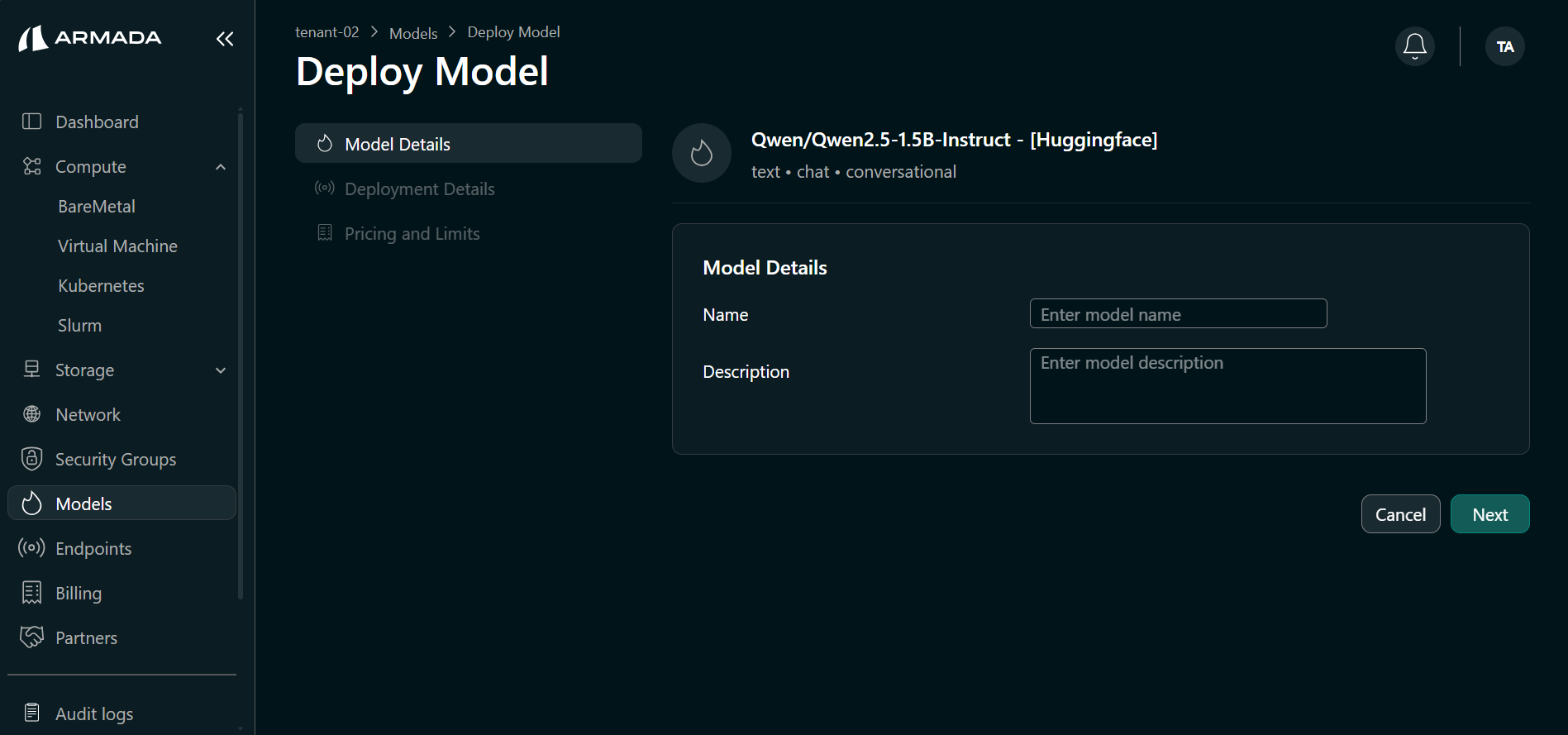
Step 2: Model Details
- Enter a model Name (e.g.,
qwenmodel) and Description. - Click Next.
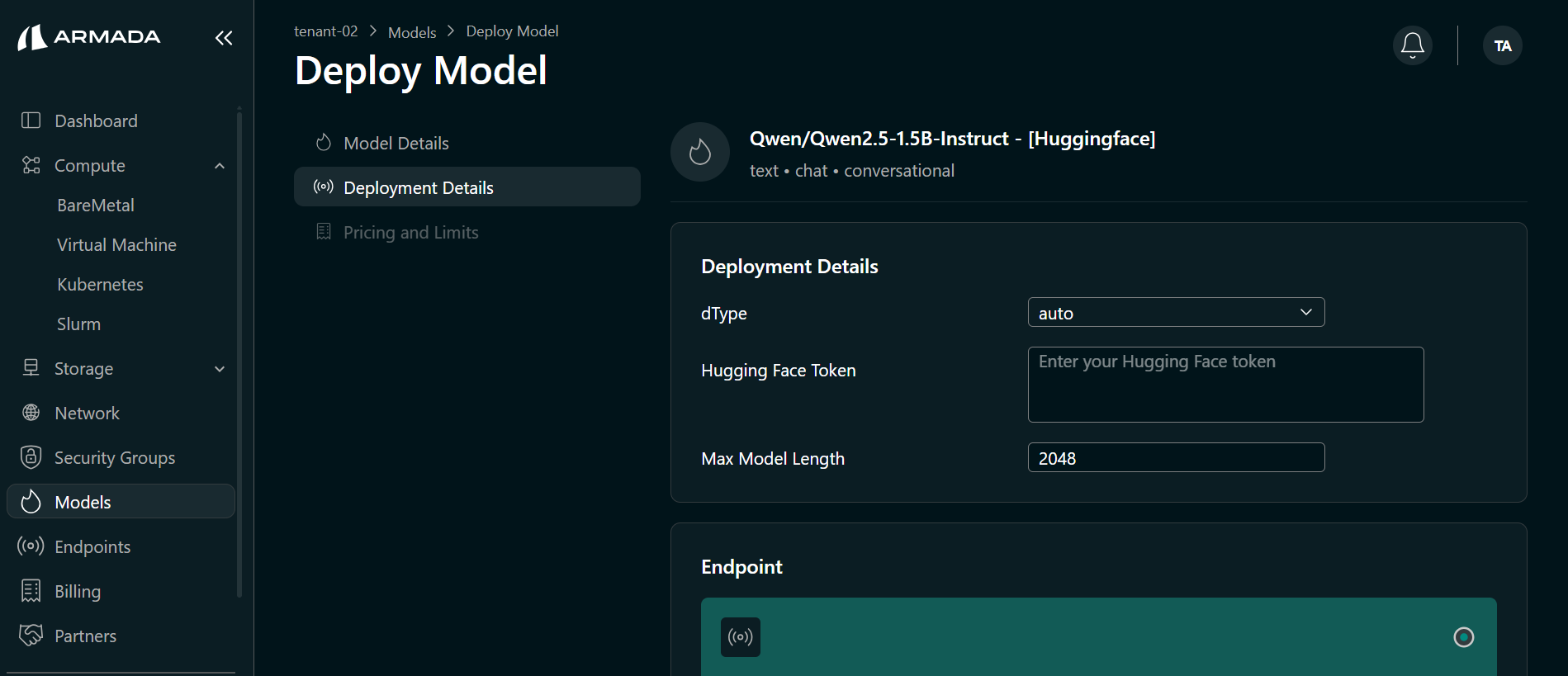
Step 3: Model Configuration
- Select the dType (data type) from the dropdown.
- Enter your Hugging Face Token to download the model.
- Enter the Max Model Length.
info
- dType controls the numerical precision used for the model's weights during inference — lower precision (e.g., float16) reduces GPU memory usage and speeds up inference, while higher precision (e.g., float32) preserves accuracy. Select auto to use the model's original precision.
- Max Model Length is the maximum number of tokens (input + output combined) the model can process in a single request. A higher value allows longer prompts and responses but requires more GPU memory.
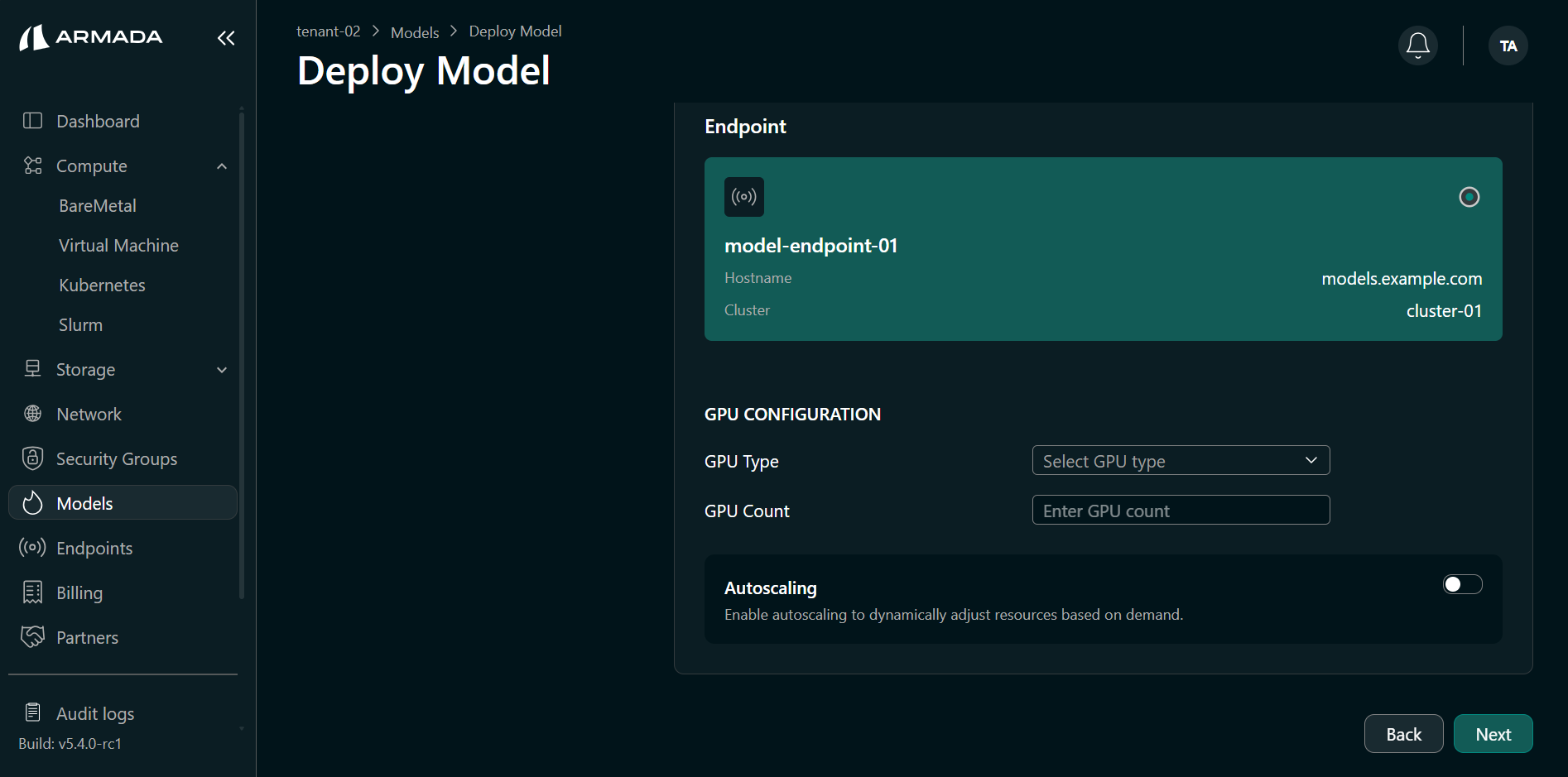
Step 4: Select Endpoint and GPU
- Select the Endpoint that will expose this model.
- Select the GPU type (e.g., L4).
- Set GPU count (e.g.,
1). - Click Next.
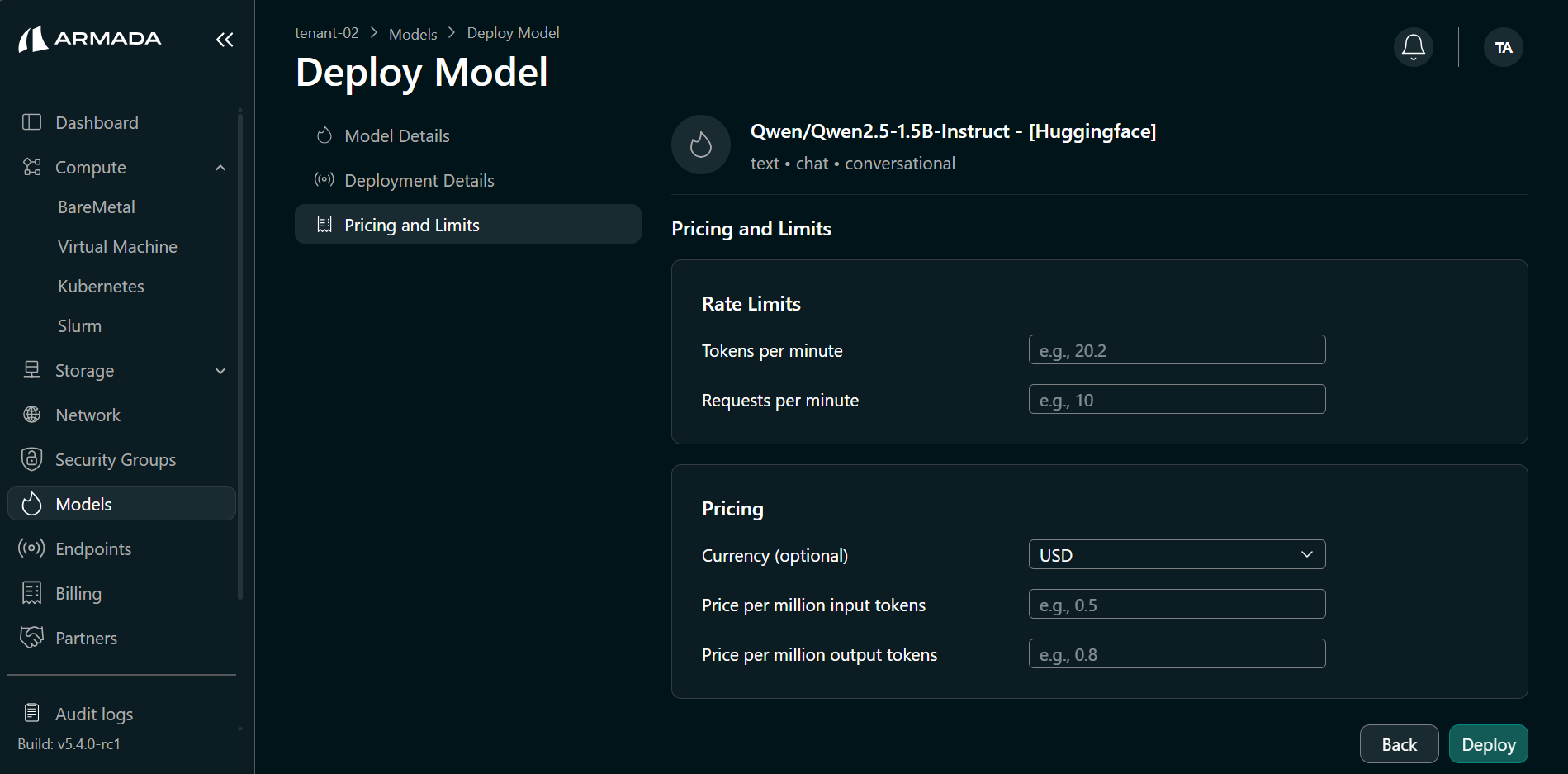
Step 5: Set Rate Limits and Pricing
- Configure the following rate limits and pricing:
- Token per minute — e.g.,
4000000 - Request per minute — e.g.,
50 - Currency — e.g.,
USD - Price per million input tokens — e.g.,
1 - Price per million output tokens — e.g.,
1
- Token per minute — e.g.,
- Click Deploy.
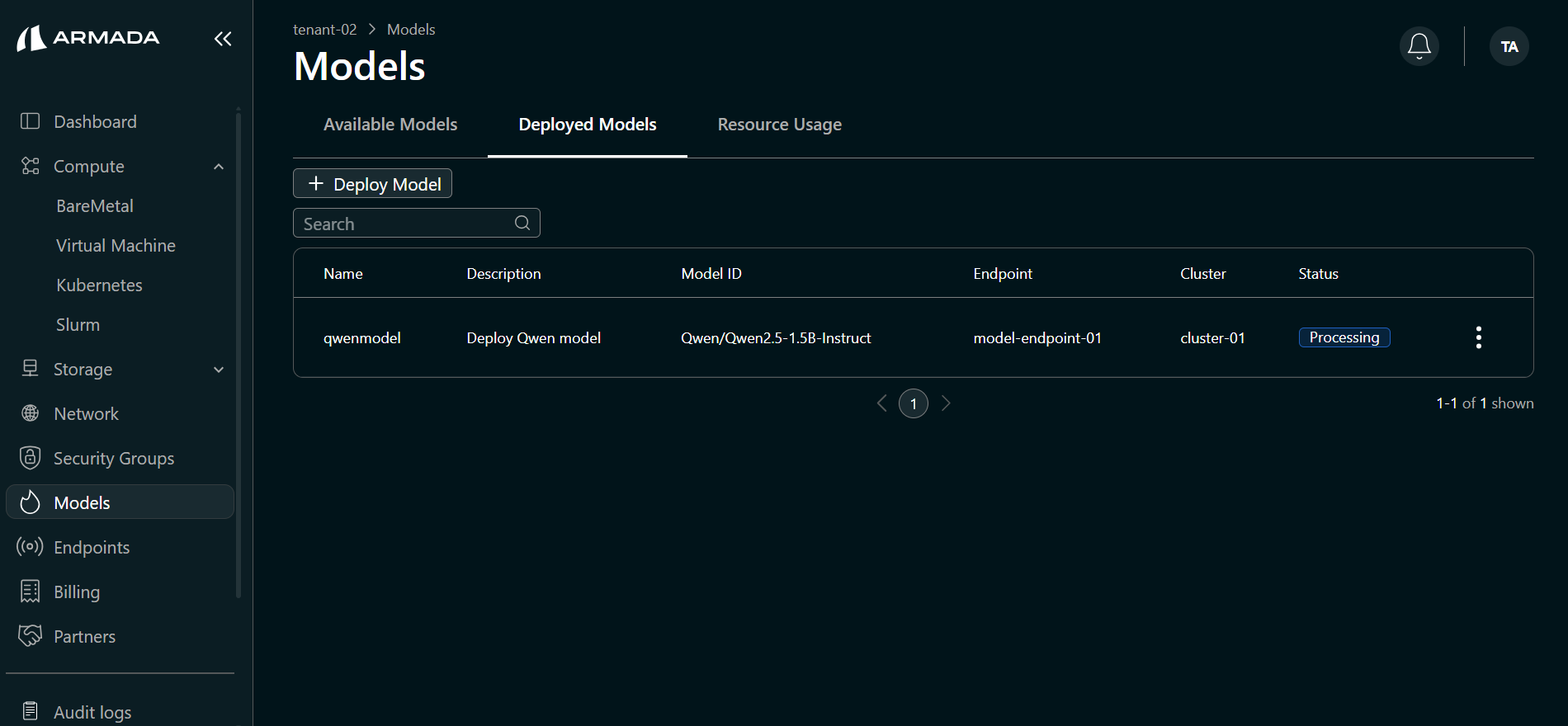
Step 6: Monitor Deployment
Deployment typically takes 10–15 minutes.
- Watch the deployment progress in the UI. The model status will initially show Processing.
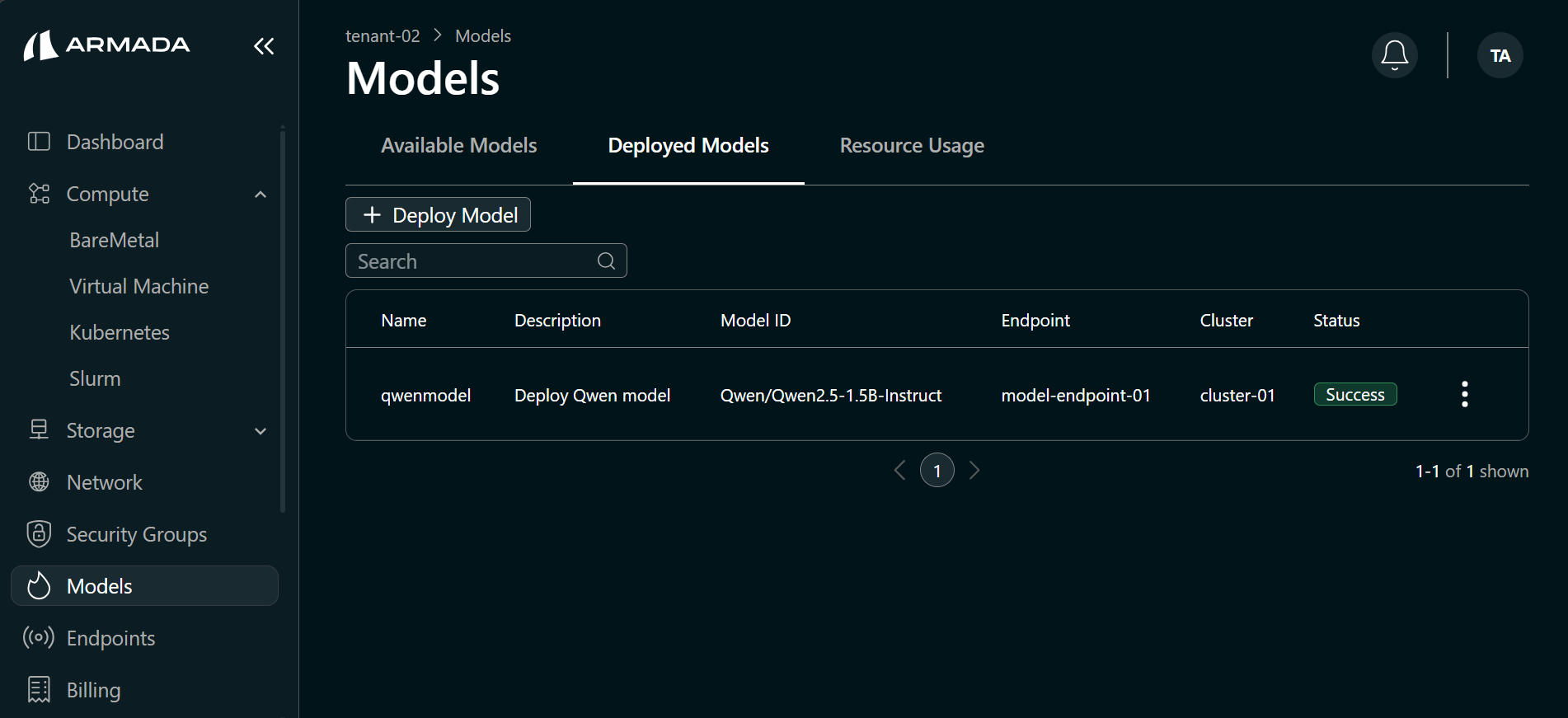
- When deployment completes successfully, the model status shows Running.
Next Steps
- Deploy NIM Model — Deploy GPU-optimized NVIDIA NIM models.
- Deploy Azure ML Model — Deploy models from the Azure ML catalog.
- Access Model Playground — Test deployed AI models interactively by sending prompts and inspecting responses in real time.