NVSwitch and NVLink Secure Partition
Bridge manages NVSwitch-equipped HGX servers by integrating with NVIDIA Fabric Manager to configure NVLink Secure Partitions. This enables per-tenant GPU isolation at the fabric level, allowing each tenant to use full NVLink bandwidth within their allocation with no cross-tenant communication.
GPU Interconnect Architecture
IOMMU-Based Isolation (PCIe Servers)
On servers without NVSwitch — such as H100 PCIe or A100 PCIe systems — Bridge enforces GPU isolation using the IOMMU (Input–Output Memory Management Unit). IOMMU acts as a hardware boundary between devices and system memory: GPUs are assigned to specific IOMMU groups and passed through directly to the tenant's VM, preventing any GPU assigned to one tenant from accessing memory belonging to another.

Bridge configures IOMMU-based GPU passthrough as part of VM provisioning on PCIe GPU servers. This model is proven and secure, but introduces a limitation in multi-tenant environments: NVLink is disabled for partial GPU allocations. When only a subset of GPUs is assigned to a VM, GPU-to-GPU traffic falls back to PCIe, significantly reducing performance for multi-GPU workloads.

NVLink and NVSwitch (HGX Servers)
NVLink is NVIDIA's dedicated GPU-to-GPU interconnect, delivering bandwidth measured in hundreds of gigabytes per second per GPU — far exceeding PCIe. NVLink allows GPUs to exchange data directly, bypassing the CPU, and is critical for workloads such as large language model training, distributed inference, and vision-language pipelines.
NVSwitch extends NVLink from point-to-point connections to a full non-blocking any-to-any fabric across all GPUs in the system. On HGX platforms, multiple NVSwitch chips work together to deliver terabytes per second of aggregate bandwidth, ensuring uniform and predictable GPU-to-GPU communication at any scale.
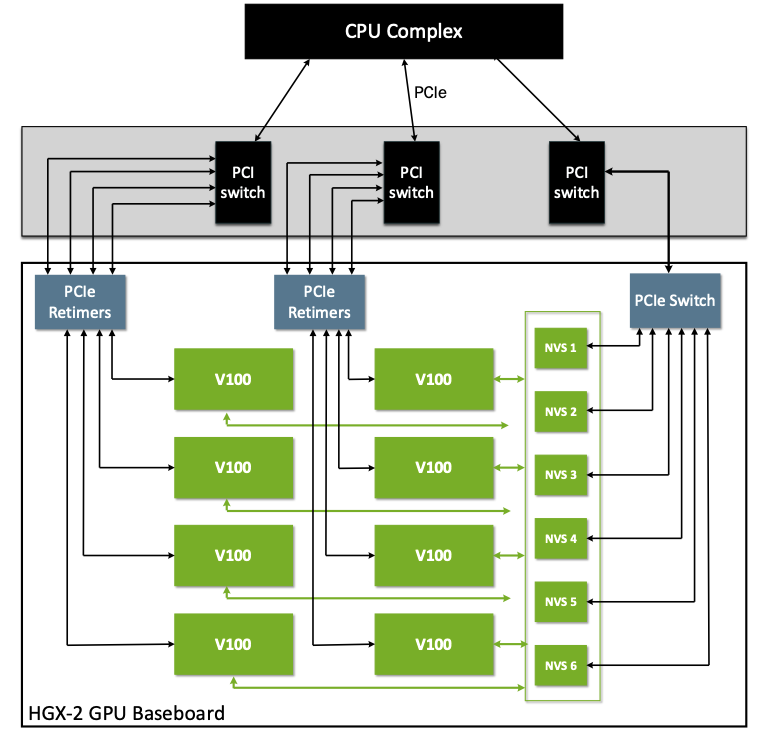
The Multi-Tenancy Challenge
The physical NVSwitch fabric connects all GPUs in the system. Without additional controls, GPUs assigned to different tenants are on the same fabric — creating a potential path for cross-tenant GPU communication.
The conventional response is to disable NVLink entirely when GPUs are split across tenants. This preserves isolation but forces all GPU-to-GPU traffic back onto PCIe, negating the performance benefits of NVSwitch and effectively reducing powerful multi-GPU servers to single-tenant machines.
| Configuration | Isolation | GPU-to-GPU Bandwidth |
|---|---|---|
| NVLink disabled (PCIe fallback) | Strong | Low (PCIe limited) |
| NVLink enabled, no partitioning | None | High (NVLink) |
| NVLink Secure Partition (Bridge) | Strong (hardware) | High (NVLink) |
NVLink Secure Partition
Bridge resolves this challenge by configuring NVLink Secure Partitions on the NVSwitch fabric through NVIDIA Fabric Manager. Fabric Manager programs the NVSwitch routing tables to create logical NVLink domains within a single physical system:
| Property | Description |
|---|---|
| Intra-partition NVLink | Full NVLink bandwidth active between all GPUs within the same partition |
| Inter-partition blocking | NVLink traffic between partitions completely blocked at the hardware routing level |
| Hardware enforcement | Isolation enforced by NVSwitch hardware, not software |
| Transparent to workloads | From the workload's perspective, GPUs appear as a fully connected group with no performance penalty |
Each tenant receives a private, high-bandwidth NVLink fabric slice while remaining fully isolated from neighboring tenants at the hardware level.
Bridge Integration with NVIDIA Fabric Manager
Bridge integrates with NVIDIA Fabric Manager to automate the NVSwitch partition lifecycle as part of compute allocation.
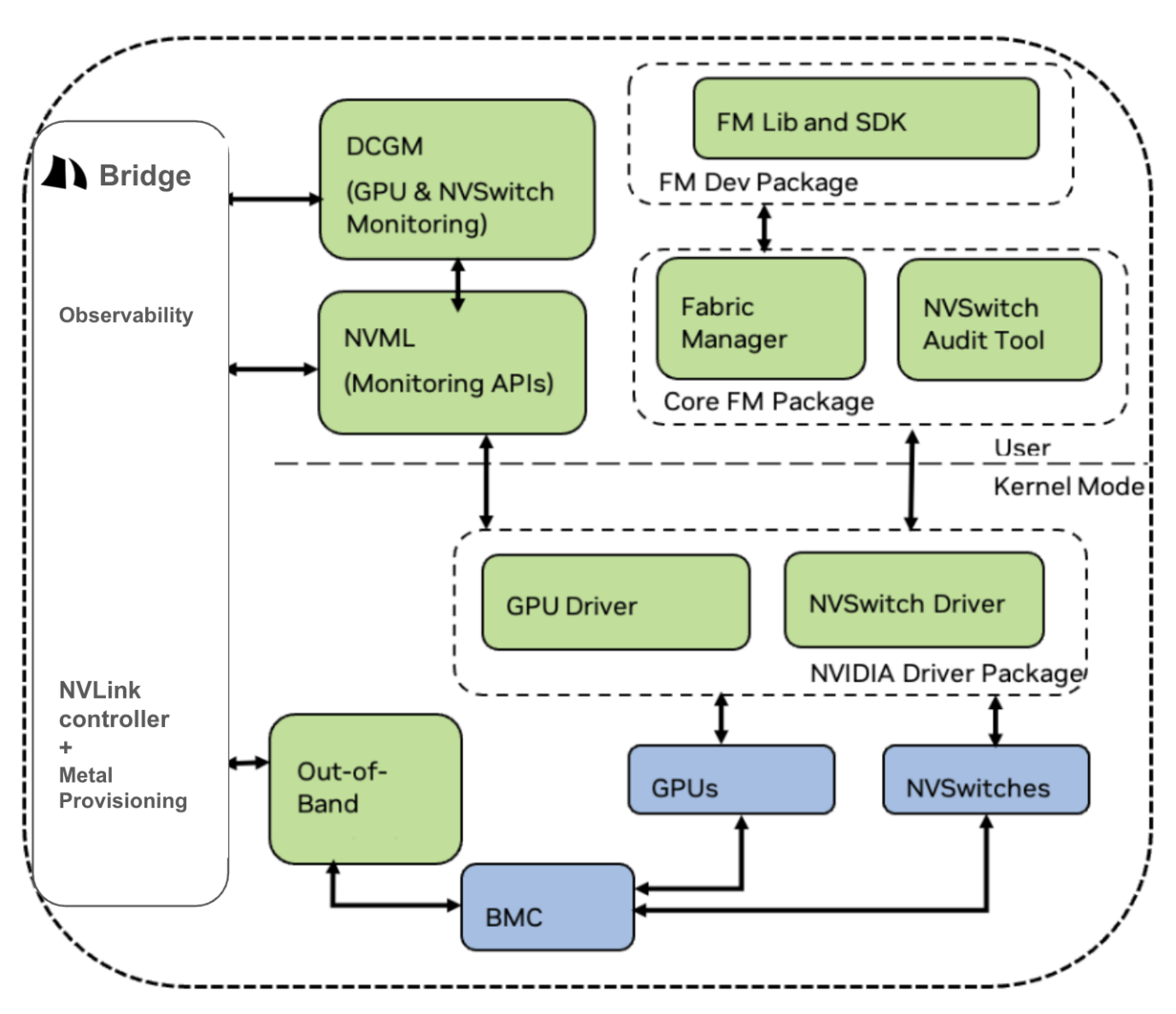
Bridge manages Fabric Manager through two controllers:
NVLink controller + Metal Provisioning:
- Communicates with Fabric Manager via the out-of-band (OOB) network and BMC.
- Creates and removes NVLink partitions as compute is allocated and deallocated.
- Ensures NVSwitch routing tables are programmed correctly for each tenant's GPU group.
Observability:
- Integrates with DCGM (Data Center GPU Manager) for GPU and NVSwitch monitoring.
- Integrates with NVML (NVIDIA Management Library) for programmatic GPU metrics access.
- Exposes GPU and NVSwitch health metrics on Bridge dashboard.
Partition Lifecycle
| Event | Bridge Action |
|---|---|
| Compute allocated to tenant | Bridge calls Fabric Manager to assign the tenant's GPUs to an isolated NVLink partition |
| Compute deallocated | Bridge removes the GPU GUIDs from the tenant's partition, immediately revoking NVLink fabric membership |
NVLink Secure Partitions are created and removed automatically with each compute allocation — no manual Fabric Manager configuration is required.
Combined Isolation Model
Bridge enforces GPU isolation at two hardware levels simultaneously:
| Layer | Mechanism | Enforced By |
|---|---|---|
| Host level | IOMMU device passthrough — GPU memory mapped exclusively to the tenant's VM | CPU/chipset hardware |
| Fabric level | NVLink Secure Partition — NVLink routing blocked between tenant GPU groups | NVSwitch hardware via Fabric Manager |
Together, these two layers guarantee that a tenant's GPUs cannot access memory or communicate over NVLink with GPUs belonging to any other tenant, while preserving full NVLink performance within each tenant's allocation.
Supported Hardware
NVSwitch-based GPU interconnect and NVLink Secure Partition are available on NVIDIA HGX systems:
| Platform | NVSwitch | NVLink Secure Partition |
|---|---|---|
| HGX H100 | Yes | Yes |
| HGX H200 | Yes | Yes |
| HGX B200 | Yes | Yes |
| GB200 NVL72 | Yes | Yes |
| H100 PCIe / A100 PCIe | No | Not applicable (IOMMU only) |
Related Pages
- Networking Overview — Tenant network isolation architecture
- DPU Overview — Complementary host-level security offloading with BlueField-3